
6 Best Data Flow Optimization Tips in Apache NiFi
402 VIEWS , 1 views today

Apache NiFi is a robust, open-source platform for automating the flow of data between disparate systems. Some of its common use cases include data ingestion, data integration, data transformation, data enrichment, data flow management, and real-time data processing. With its user-friendly, drag-and-drop interface, designing, controlling, and monitoring data flows become extremely easy.
But what is the data flow?
A data flow is the primary operational structure in Apache NiFi. It is simply a pipeline or workflow through which data is extracted from the source, processed/transformed, and loaded into the destination. You can design a data flow by combining multiple elements, as follows:

To ensure efficient and reliable data movement between different systems, it becomes necessary to optimize data flows in Apache NiFi. In this blog, we shall walk you through some of the best data flow optimization tips in Apache NiFi.
Why Optimize Data Flows in Apache NiFi?
Let us shed light on some major reasons for optimizing data flows in Apache NiFi.
- Boost Performance & Increase Throughput
Optimizing NiFi flows ensures faster processing of data without any bottlenecks. It prevents the overuse of CPU, memory, and disk I/O, significantly improving performance. Moreover, optimized flows enable seamless handling of large volumes of data, resulting in consistently high throughput and operational efficiency.
- Reduce Latency
As optimized flows facilitate real-time data processing, the delay between data ingestion and delivery is significantly reduced. This leads to reduced latency, which is inevitable for time-sensitive applications.
- Improve Scalability
Optimized data flows can adapt to handling increasing data volumes by distributing workloads evenly across different NiFi cluster nodes. Consequently, they can efficiently meet your growing data processing demands without compromising performance.
- Lower Operational Costs
As discussed already, optimization of data flows leads to efficient resource utilization, i.e., minimizes the use of CPU, memory, and storage resources. This significantly lowers operational costs.
Top 6 Data Flow Optimization Tips in Apache NiFi
Now that you know the reasons for optimizing data flows in Apache NiFi, let us focus on some of the best data flow optimization practices.
1. Design Data Flows with Modularity
In general terms, the modular approach breaks down complex tasks into small, manageable pieces. When it comes to designing data flows, this approach makes it easy to debug, reuse, and scale your data flows.
Always design your data flows by keeping modularity in mind. Instead of creating a single flow for an entire data transfer process between two systems, it is always better to break it down into groups. This means creating different process groups for data ingestion, data transformation, and data delivery.
In this case, the best practice is to leverage input/output ports to enable seamless communication between different process groups (intended for data ingestion, transformation, & delivery).
2. Leverage the Back Pressure Mechanism to Avoid Bottlenecks
In Apache NiFi, back pressure is a mechanism that stops data (FlowFiles) from flowing fast into the part of a system where it can’t be handled. This prevents the system from being overwhelmed with excessive data, which may otherwise lead to breakdown.
When you use back pressure, you can set limits on how much total data (size of FlowFiles) can be present in a particular queue. If that limit is reached, NiFi automatically stops more data flowing into that part of the system.
Let’s understand the back-pressure mechanism with an example.
Example: Consider you have a system that collects data from various sources and stores it in a database. If the database is slow to receive and process data, the queue for storing that data gets full.
If you haven’t used the back pressure mechanism, more and more data would pile up in the system, leading to crashes or failure. However, with back pressure, Apache NiFi stops the flow of incoming data when the queue reaches its limit. This allows the database to process the existing data from the queue, preventing system crashes or data loss.
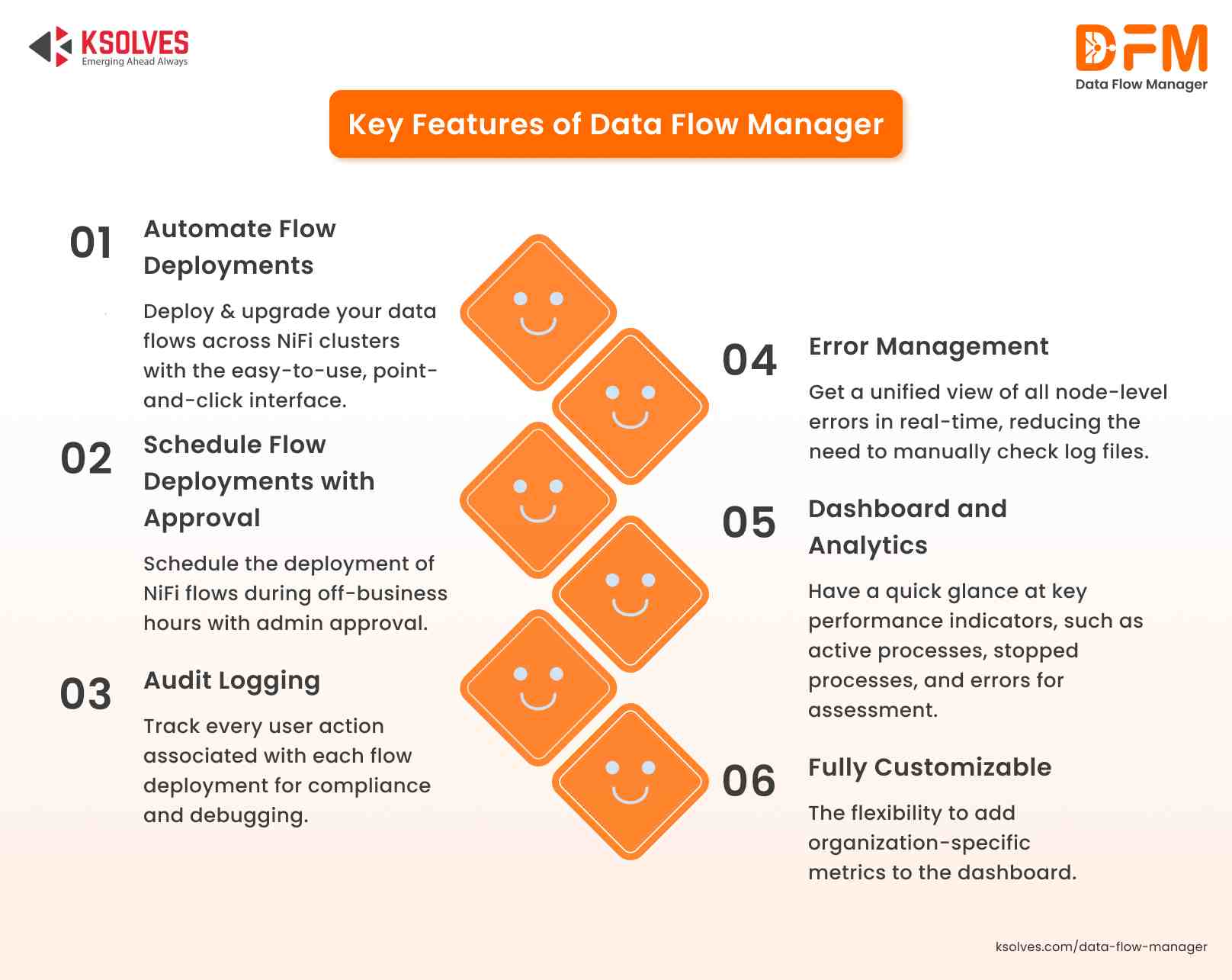
3. Automate Flow Deployments
Manual flow deployment consumes ample time as it requires you to export the flow from one NiFi cluster, import it to another, and tune flow parameters and configurations manually. This increases the likelihood of manual errors, which can lead to inconsistencies affecting data operations.
The best practice is to automate NiFi flow deployments using a tool called Data Flow Manager. Built for on-premise Apache NiFi and developed by Ksolves India Limited, Data Flow Manager streamlines the deployment and promotion of data flows across NiFi clusters in minutes. It entirely eliminates the hassle of creating and configuring controller services for flows using the NiFi UI.
In addition, it integrates with AI to empower NiFi users to generate data flows instantly just by entering the source, destination, and description in natural language.
For example, a flow in the development environment can be easily deployed to the staging or production environment in minutes. You do not have to write complex Ansible scripts.
What’s more interesting is that the tool allows you to choose the desired version of the flow to be deployed.
4. Leverage NiFi Clustering for Scalability
Clustering refers to the process of combining multiple modes of an Apache NiFi cluster to run the same data flow parallelly.
In this case, your modular data flow comes in handy. You can partition your modular data flow into groups and assign them to different nodes to manage the ingestion, processing, and distribution of data simultaneously. This, indeed, accelerates the entire pipeline for seamless data transfer and ensures optimal resource utilization.
Why does it matter?
With the distribution of workloads across multiple nodes, clustering allows you to scale out your NiFi deployment to ensure high throughput & fault tolerance. It lets you process massive volumes of data efficiently, reducing the risk of bottlenecks.
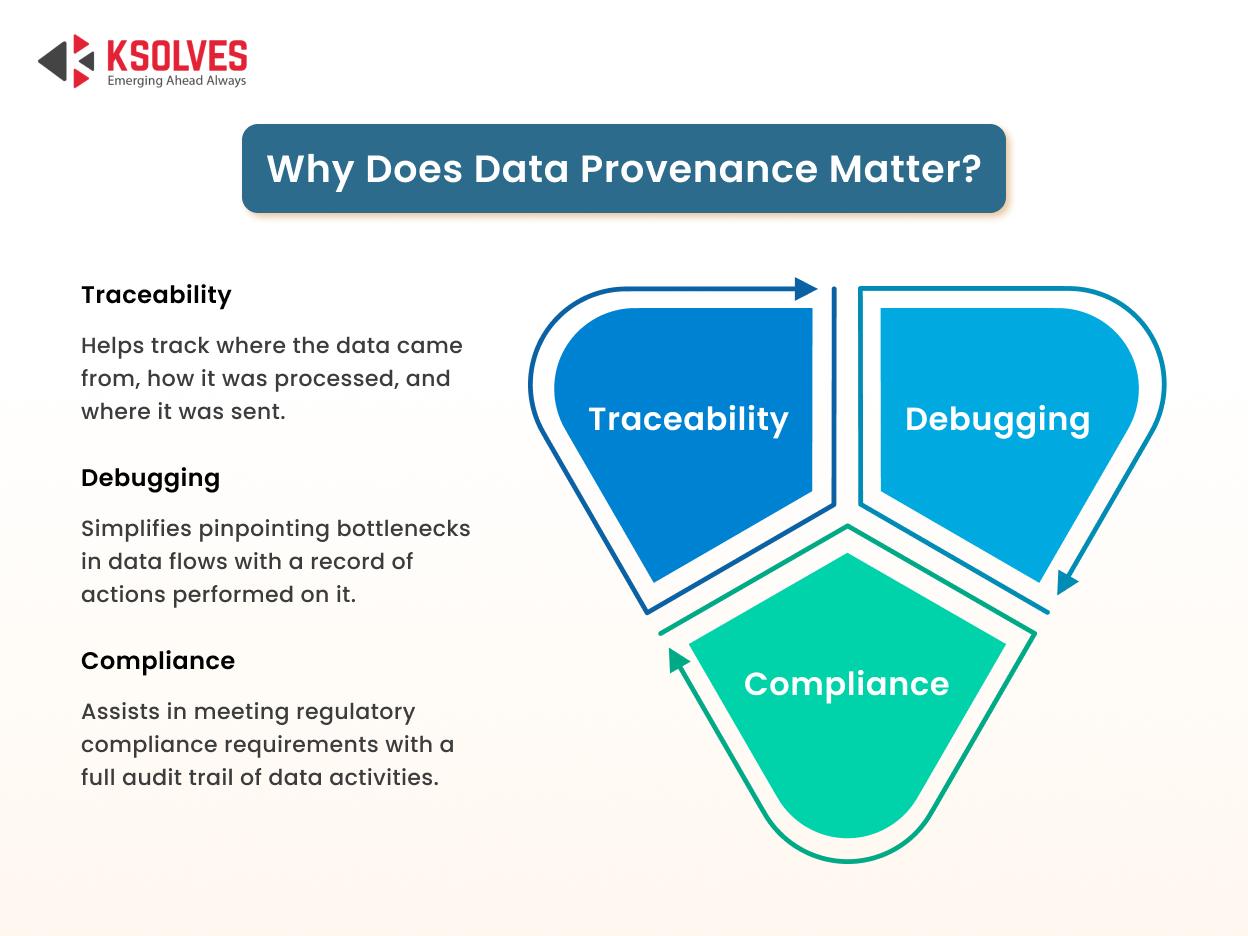
5. Utilize Data Provenance for Debugging
Data provenance, also known as data lineage, refers to the historical record of data. It logs all the transformations on data and the various processes it goes through, enhancing transparency and accountability.
In Apache NiFi, data provenance provides detailed insights into actions performed on FlowFiles. It includes the following information:
- Event types: Records various events such as FlowFile creation, modification, cloning, fork, etc.
- Timestamps: The time when a specific event was created.
- Processor information: Which processor handled the specific event.
- Attributes: Metadata associated with FlowFiles at different stages.
Content Changes: the snapshots of content at various stages.
Let us understand data provenance in Apache NiFi with a simple example.
Example: Consider running an e-commerce website. To maintain sales information, you process customer order data by applying a series of transformations and store it in a database. With data provenance, you can track when the data was received, how it was transformed, and verify whether it was successfully loaded into the database.
6. Secure Your Data Flows
Data security is paramount in today’s digital world. Consequently, securing your data flows becomes necessary, especially for sensitive and regulated information. Here are some of the best tips to secure your data flows:
- Leverage TLS certificates to encrypt communications between nodes.
- Implement role-based access control (RBAC) to ensure that only authorized users can modify data flows. With Data Flow Manager’s intuitive UI, implementing role-based access control becomes straightforward.
Conclusion
These were some of the best data flow optimization tips in Apache NiFi. By optimizing your NiFi flows, you ensure that your data pipelines are reliable, scalable, and capable of handling large volumes of data. Investing time in data flow optimization will definitely pay back in terms of high performance, throughput, and reduced latency.
Ready to take a deep dive into Data Flow Manager? In this exclusive video, our CTO, Manish Gurnani, walks you through a hands-on step-by-step demo on how to get started with DFM and make the most of its powerful capabilities.
Data Flow Manager can be your great companion in elevating the features of your NiFi instance. From automating flow deployments and promotion to implementing role-based access control and audit logging, it simplifies optimization tasks for you. Besides, it significantly saves deployment times, minimizes downtime during flow upgrades, and reduces manual efforts for flow management. Book your demo today!
