
Iceberg Ahead: Exploring the Basics of Apache Iceberg for Data Management
Big Data
5 MIN READ
August 5, 2024

Is streamlining data lake management causing you stress? Enter the dynamic world of data management with Apache Iceberg, an innovative framework tailored to navigate the complexities of contemporary data lakes. Leveraged by 591 companies, Apache Iceberg provides a robust solution for structuring, administering, and querying extensive datasets with unparalleled efficiency.
Traditional methods falter as data volumes surge, leading to inefficiencies and scalability hurdles. Apache Iceberg addresses these challenges head-on, offering a comprehensive framework that optimizes workflows, ensures reliability, and facilitates seamless expansion. Read this blog to understand how to unlock the full potential of your data ecosystem.
What is the Apache Iceberg?
Apache Iceberg is an open-source table format tailored for Big Data, specifically targeting the drawbacks of conventional formats such as Apache Parquet and Apache Avro. Offering a robust and scalable solution, it facilitates managing and analyzing extensive datasets within distributed systems, marking a significant advancement in data organization and processing capabilities.
Apache Iceberg Data Lake Architecture
Iceberg Data Lake Architecture revolutionizes data management and analysis by providing a comprehensive framework tailored for modern data lakes. With its innovative features and components, including the optimized table format, metadata management, query engine, and seamless integration with popular data processing frameworks, Iceberg enables organizations to efficiently manage and analyze vast datasets with enhanced performance, reliability, and scalability. This empowers businesses to extract actionable insights and drive informed decision-making, unlocking the full potential of their data ecosystems.
How Does Apache Iceberg Work?
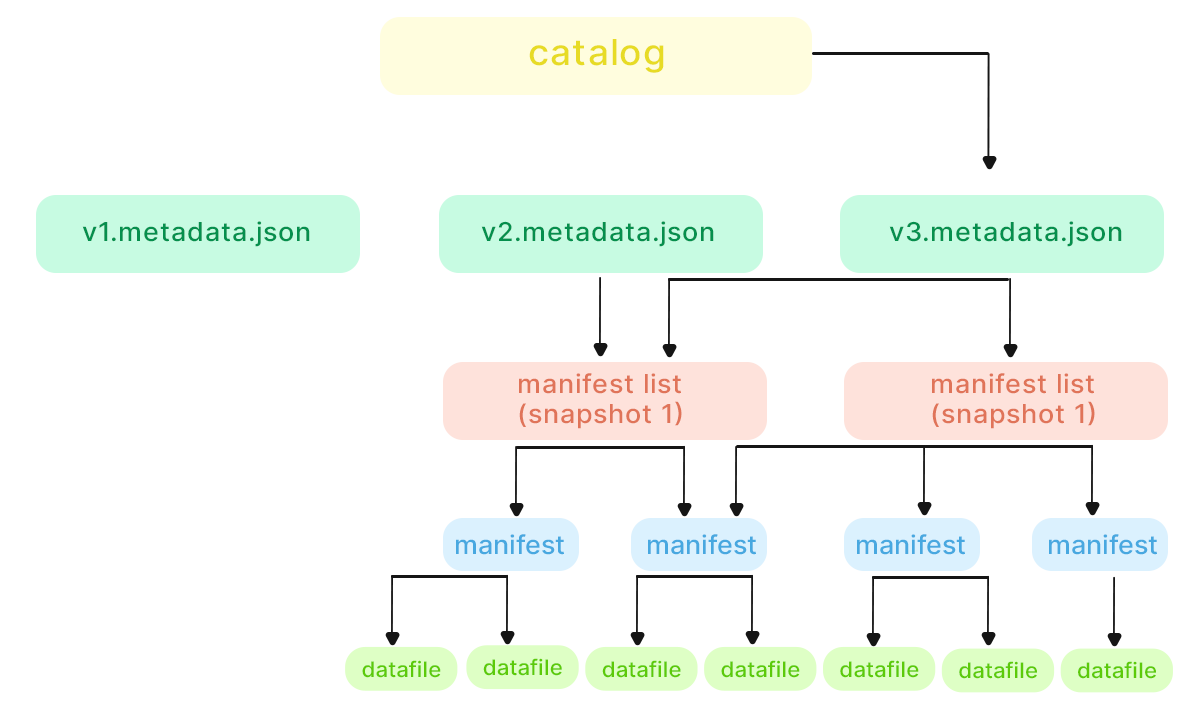
Apache Iceberg offers a comprehensive framework for managing and analyzing vast datasets within data lakes. Apache Iceberg for large-scale analytics is essential, as it can revolutionize with its innovative architecture and performance optimization. Also, Apache Iceberg for historical data analysis ensures efficiency and scalability in data lake architecture.
Key Components:
- Iceberg Catalog: Manages table lists and points to the latest metadata location, typically metadata.json.
- Metadata.json: Holds table details like schema, partitioning scheme, and snapshot history.
- Manifest List: Corresponds to snapshots, aggregating statistics for each manifest to facilitate partition pruning.
- Manifests: Bundles data files with statistics, aiding min/max filtering for efficient query execution.
Apache Iceberg is a pivotal solution for organizations seeking to optimize their data lake architectures for enhanced performance and scalability.
Read More: Apache NiFi Vs Apache Kafka Comparison: Features & Functionalities
Top Apache Iceberg Features
1. User Experience:
Schema Evolution: Iceberg enables seamless schema evolution by allowing users to modify table columns without rewriting the table. It assigns unique IDs to new columns, ensuring changes are free of side effects.
Hidden Partitioning: Apache Iceberg abstracts table partitioning, eliminating the need for users to understand file layout beforehand. It dynamically adjusts schema and partition as data scales, simplifying querying.
Time Travel: Iceberg’s versioning feature preserves data changes, facilitating easy rollback to stable versions. This ensures data integrity and enables comparison between current and previous data states.
2. Reliability
1. Snapshot Isolation: Iceberg ensures consistent dataset reads by providing a snapshot of the last committed values during reads, preventing conflicts during concurrent updates.
2. Atomic Commits: Iceberg guarantees data consistency by completing updates entirely or discarding changes to avoid partial updates.
3. Reliable Reads: Each transaction in Iceberg generates a new snapshot, allowing readers to access multiple versions for reliable queries.
File-level Operations: Unlike traditional catalogs that require tedious directory traversal, it enables direct updates to individual records without modifying the folder structure.
3. Performance
Iceberg’s performance features simplify data management by storing metadata and statistics for every table file, enabling efficient query scan planning.
It utilizes manifest files and a manifest list to track files in a snapshot, utilizing partition min and max values for fast scan planning.
Read More: Migration of Legacy Kafka to latest Confluent Kafka
Benefits of Apache Iceberg
1. Optimized Query Performance
Apache Iceberg performance optimizations are one of the most important benefits of the technology. Apache Iceberg employs various performance enhancement techniques. It enables file partitioning based on multiple fields, reducing query scan volumes. With predicate pushdown support, data filtering occurs at the storage level, minimizing data transfer and processing overhead. Iceberg facilitates incremental scans, reading only changed file portions since the last query to enhance efficiency. Additionally, automatic compaction reduces fragmentation and access overhead.
2. Meta Data Management
Apache Iceberg seamlessly integrates with widely used data processing frameworks like Apache Spark, Apache Flink, and Presto. This compatibility enables developers to incorporate Iceberg into their current data pipelines with minimal adjustments, simplifying adoption and deployment.
3. Schema Evolution
An essential aspect of Apache Iceberg lies in its robust support for seamless schema evolution. Iceberg is vital for data governance as well. This feature permits additions, deletions, and updates to table schemas without impacting existing data integrity. With Iceberg’s capability, data remains accessible and queryable despite ongoing schema modifications, ensuring data governance integrity.
4. ACID Transaction Support
Iceberg extends ACID guarantees to large-scale datasets, offering transactional support. This ensures data integrity and consistency, which is important for applications demanding precise data accuracy and reliability. This feature is invaluable for maintaining data reliability amidst dynamic querying and updates, particularly in expansive organizations with multiple concurrent operations.
Some Apache Iceberg use cases
1. Iceberg Data Lake
Apache Iceberg emerges as an optimal choice for data lake management, providing a structured and efficient approach to handling extensive raw data volumes. Its capabilities facilitate scalable data storage, enhance query performance, and enable smooth schema evolution, empowering enterprises to harness their data lakes for valuable analytical insights.
2. Data Lake House
Iceberg extends its utility to creating data lakehouses, amalgamating prime features from data warehouses and data lakes. It provides ACID transactional support and performance enhancements for a data lakehouse framework.
3. Data Governance
Apache Iceberg stands pivotal for data governance with its centralized metadata administration and transactional capabilities. Ensuring data integrity, compliance, and security throughout operations, Iceberg emerges as a cornerstone for organizations seeking robust data governance strategies.
Conclusion
In conclusion, exploring the fundamentals of Apache Iceberg reveals a dynamic solution for contemporary data management challenges. With its robust features and seamless integration with popular data processing frameworks like Apache Spark, Iceberg emerges as a cornerstone for efficiently managing and analyzing vast datasets within Data Lakes. As organizations navigate the ever-evolving data landscape, Apache Iceberg stands as a beacon, unlocking the full potential of their data ecosystems and driving actionable insights for informed decision-making.
For Apache Spark development services and case studies, consider partnering with Ksolves. Contact us today to explore how we can help optimize your data management processes.





AUTHOR
Big Data
Anil Kushwaha, Technology Head at Ksolves, is an expert in Big Data and AI/ML. With over 11 years at Ksolves, he has been pivotal in driving innovative, high-volume data solutions with technologies like Nifi, Cassandra, Spark, Hadoop, etc. Passionate about advancing tech, he ensures smooth data warehousing for client success through tailored, cutting-edge strategies.
Share with