HDFS Overview: Everything You Need To Know
Hadoop
5 MIN READ
August 9, 2022
![]()

With the growing data velocity, the data exceeds the machine’s storage. The best solution to this issue is to keep the data across a network of machines. These types of filesystems are known as distributed file systems. Because data is across the network, all network complications occur. To tackle the issue, Hadoop plays an essential role. It is known for providing the most reliable filesystems. Hadoop Distributed File System is also known as HDFS; it has a unique design that provides storage for significantly large files.
What Is HDFS?
Hadoop distributed file system is the primary data storage system; it helps to manage large amounts of data and supports associated Big Data analytics applications.
The large-scale software-based infrastructure of Google inspired the Hadoop file system. This tool provided cost-effective and scalable storage systems for MapReduce workloads. It helps to implement a distributed file system that can provide you with high-performance access to data across highly scalable Hadoop clusters.
Most people tend to mistake it for Apache HBase. Apache HBase is a column-oriented non-relational database management system. It sits on top of the HDFS and can support real-time data needs with its in-memory processing engine.
Hadoop Distributed File System can provide you with high-throughput data access. It is suitable and reliable for large-scale data sets. This tool can relax the POSIX constraints to stream the file system data. HDFS was developed as the infrastructure of the Apache Nutch Search engine project. This tool is part of the Apache Hadoop Core Project.
HDFS can accept data in any format regardless of the schema, and it will also optimize the high bandwidth streaming and scales to proven the deployment of 100PB and beyond.
How Does HDFS Store Data?
When storing the data, HDFS will divide the files into blocks and store each in the form of DataNode. Several DataNodes are connected to the primary node in the cluster. It is known as the NameNode. The primary node is responsible for distributing the replicas of the data blocks across the cluster. It will also instruct you on where to locate the wanted information.
However, before the NameNode can assist you in managing and storing the data, it will initially have to split the files into manageable, smaller data blocks. This process is known as data block splitting.
Data Replication
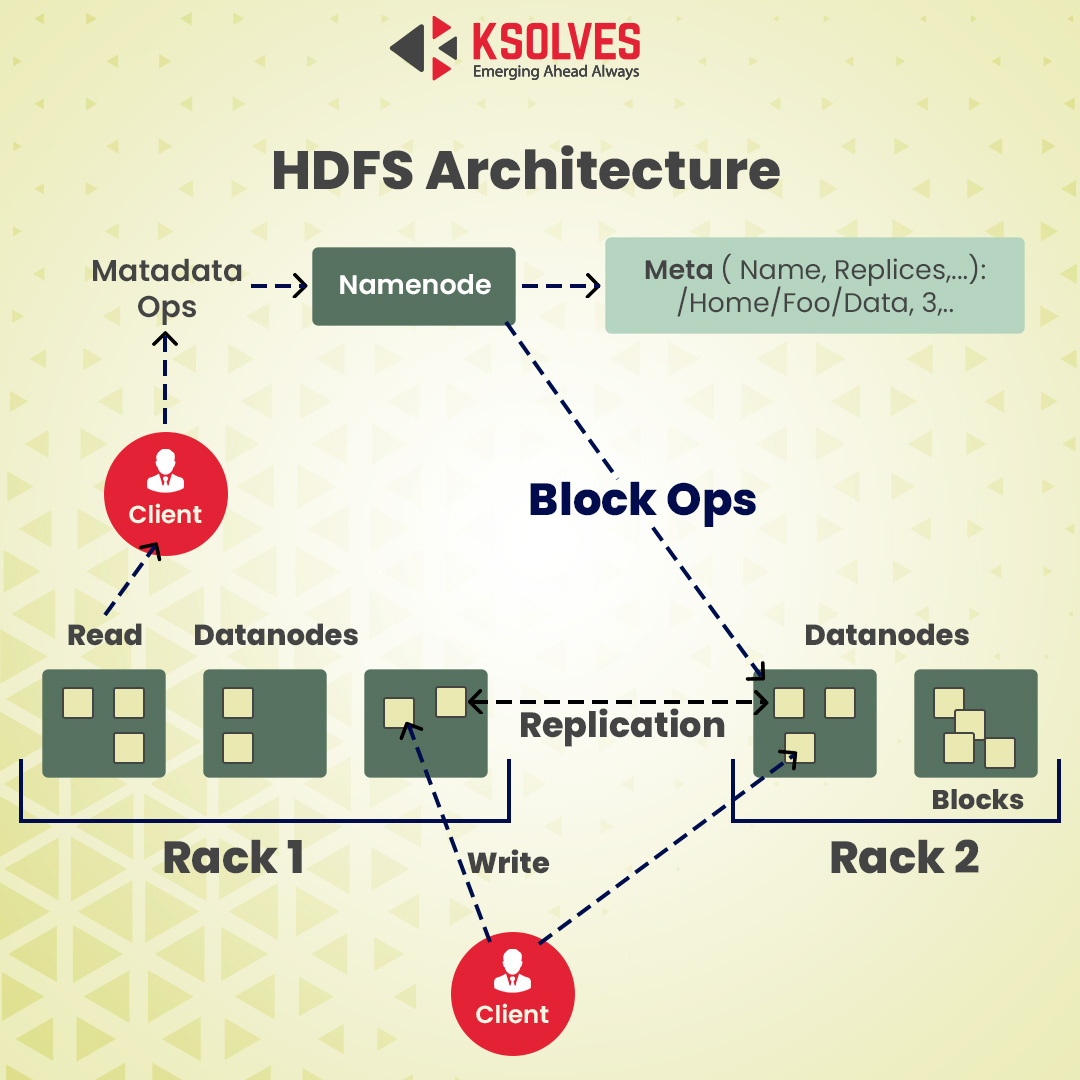
Based on the cluster’s configuration, the NameNode will create several copies of each data block with the help of the replication method. You should make at least three replicas. The master node will store the files in the separate DataNodes of the cluster. The NodesStates will be monitored closely to ensure that the data is always accessible.
To ensure high reliability, accessibility, and fault-tolerance, the developers suggest setting up three replicas with the help of the following topology:
You should initially store the initial replica on the node on the client’s location.
After that, you should store the second replica on a different rack.
And at the last step, you should keep the third replica on the primary rack as the second replica, but it will be on a different node.
Data Block Splitting

It is the default setting. A block will not be more than 128MB in size. The number of blocks depends on the original size of the file. All but the last block will be of the same size as the 128MB, while the last block will remain on the file.
For instance, an 800MB will be split into 7 blocks in which six of the blocks will be 128MB, while the seventh data block will be 32MB.
Key Features Of HDFS in Big Data
There are four primary features of HDFS in Big Data:
-
Blocks
Hadoop Distributed File System is made to support large files. When you use this tool, it will split the large files into smaller pieces. These smaller pieces are known as the blocks. These blocks contain some data you can write or read, and the tool will store each file as a block. By default, the block size will be 128MB, and Hadoop will distribute the blocks across several nodes.
-
Distributed File System
This tool is a distributed file system. It can handle large sets of data that run on commodity hardware. People can use the HDFS to scale the Hadoop cluster to thousands of nodes.
-
Data Reliability
This tool will create a replica of each data block on the nodes in any given cluster. It will provide fault tolerance. When a node fails, you can access the data on different nodes with copies of the same data in the HDFS cluster.
-
Replication
With this tool, you can replicate the HDFS data from one service to another. The replication process is for providing tolerance against fault, and the application can specify the number of replicas of the file. This process is specified during the file creation time, and you can change it later when you want to.
Files in the HDFS are written once, one writer at a time. The NameNode will make the blocks’ decisions. It also provides a heartbeat and a block report from all of the DataNodes in the cluster.
Which Industry Should Use HDFS?
Businesses and companies with large volumes of data have long started migrating to Hadoop, which is among the leading solutions for processing Big Data due to its analytics and storage capabilities. Below are the industries in which HDFS can be helpful.
Financial services:
The role of HDFS is to support the data, which is expected to grow significantly. The system is scalable without any danger of slowing the data processing.
Telecommunications:
The telecom industry is known for managing a significant amount of data, and it has to process on the petabytes scale. They can use the Hadoop analytics to manage all call data records, network traffic analytics, and other telecom associate processes.
Retail:
Because knowing your customers is the primary component of the business’s success in the retail industry, most companies can keep a significant amount of unstructured and structured customer data.
Companies can use this tool to analyze and track the data collected to help plan future inventory, marketing campaigns, pricing, and other projects.
Insurance Companies:
Medical insurance companies depend on data analysis. The process will serve as the basis for how they will formulate and integrate the policies. For the insurance industry, having information on the client’s history is invaluable. Maintaining an easily accessible database while continually growing is why most people choose the HDFS.
Energy Industry:
The energy industry always looks for ways to enhance energy efficiency. This process relies on systems such as Hadoop, and its file system will help to analyze and understand the consumption practices and patterns.
What Are The Benefits Of HDFS Integration?
This software is written in Java for distributed processing and storage of very large data sets on clusters of computers from commodity hardware. There are various benefits you will get, such as:
-
Hadoop’s Scalability
This tool is best for storing a large amount of data as it can store and distribute many data sets on countless inexpensive servers that operate in parallel. Unlike the conventional relational database systems, which cannot be scaled to process large amounts of data, this tool allows businesses to run apps on countless nodes which involve countless terabytes of data.
-
Flexible
This tool will allow your businesses to access new data sources and tap into several data types to produce value from the data. In other words, you can use this tool to derive valuable business insights from the data sources such as email conversations, clickstream data, or social media data.
Additionally, you can use this tool for various purposes such as recommendation systems, log processing, market campaign analysis, data warehousing, and fraud detection.
-
Hadoop Is Cost-Effective
This tool offers a cost-effective storage solution for businesses exploding data sets. The problem with conventional relational database management systems is that it is extremely cost-effective to a degree, and you can process a significant amount of data.
To reduce the costs, most companies in the past would have to down-sample data and classify it based on certain assumptions as to which data will be the most valuable. The raw data will be deleted as it can cost alot.
While this approach will be beneficial in the long-term, it means that when the priorities of the businesses have changed, the complete raw data set is not accessible as it will be costly to store. This tool can scale out the architecture that will be affordable for all companies.
Why Choose Ksolves?
Ksolves is the leading Apache Hadoop Development Company known for providing the best and most efficient HDFS services. With Ksolves, you can easily store a significant amount of data without straining the systems. Our experience in this field has earned us a reputation as the best company that provides the best Hadoop consulting services.
Connect with us through our website sales@ksolves.com, and our Hadoop implementation experts will contact you as soon as possible.
Conclusion
These are all the information about the HDFS and how it can help you to store a huge amount of data without any hassle. This tool is a great addition to enhance business efficiency. This tool will help you read all the data from a single machine.
=====================================================================
FAQs
Why Is It Necessary To Divide Files Into Blocks?
When you don’t divide the large files, it will put a strain on the machine to store a 100 TB file. Even if we store them, each write and read operation of the file will take a significant amount of time. But with the help of the HDFS, it will be easier to perform several reads and write operations than saving the file as a whole.
Why Replicate The Blocks In Data Nodes While Storing?
If the data node D1 crashes, you will lose the block, which makes the overall data inconsistent and faulty. So if you replicate the blocks, you will reduce the chances of errors.
What Is HDFS Block Size?
The block size that the HDFS uses will be about 128 MB. For this reason, an HDFS file is split into 128 MB chunks on different DataNodes.
![]()

Hadoop has had a significant impact on the computing industry in barely a decade. This is due to the fact […]



AUTHOR
Hadoop
Muntashah Nazir is a technical writer at Ksolves. She is an avid writer with a stronghold on detailed writing. Her expertise lies in providing a complete picture of the technology and its rewards using simple words.
Share with