Things to Consider While Working with ML- Avoid these Ten Pitfalls
AI
5 MIN READ
January 11, 2023
![]()

Machine Learning helps businesses in processing/analysing data more quickly. A Machine Learning pipeline is a series of steps that need to be followed to convert a raw ML model into a final ready-to-make predictions ML model.
The design and implementation of an ML pipeline are at the core of enterprise AI software applications. It fundamentally determines the performance and effectiveness of the enterprise. Know what things you must consider while working with Machine Learning Pipeline with our blog.
What is the Machine Learning Pipeline?
A Machine Learning pipeline is an end-to-end construct that includes raw data input, features, outputs, the Machine Learning model and model parameters, and prediction outputs.
What are ML Pipeline’s Benefits?
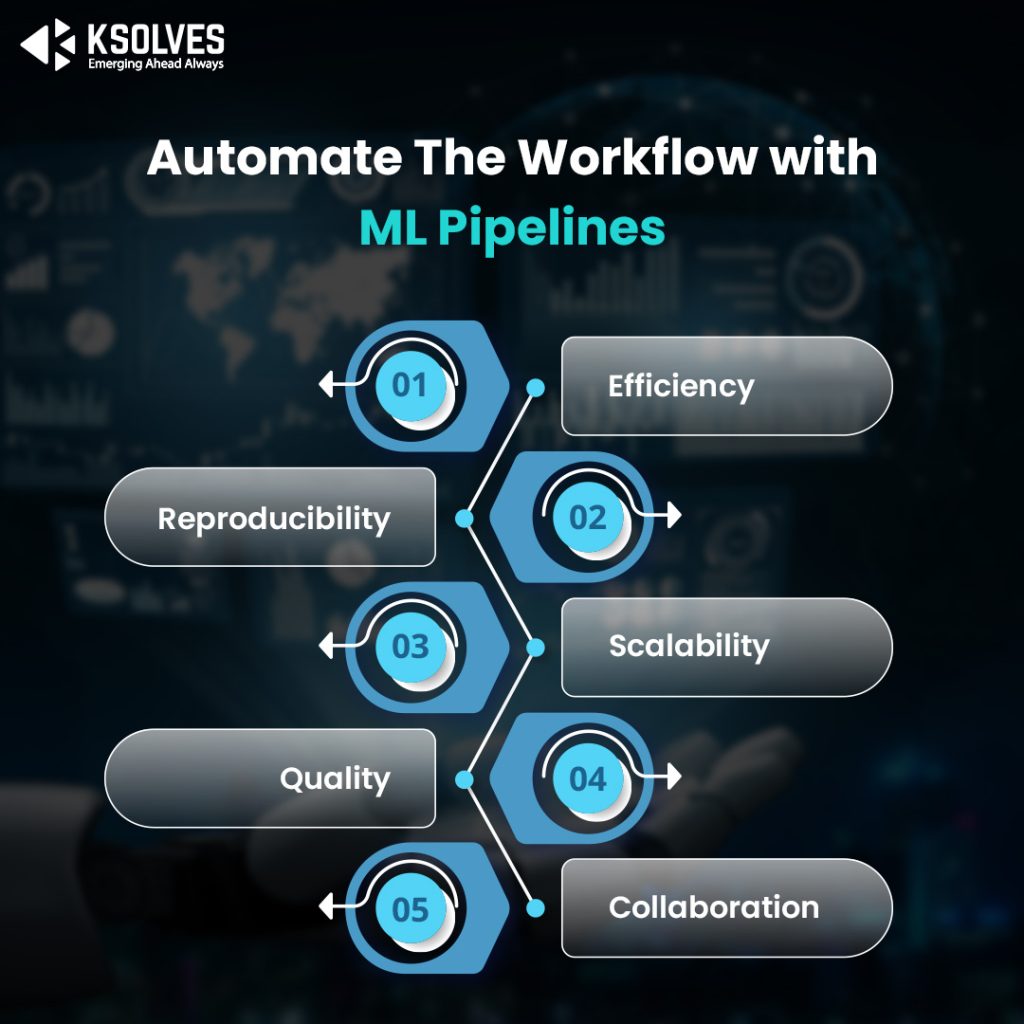
There are several benefits of using ML pipelines, as follows:
- Efficiency: It makes the process of streamlining and automating ML models easy. Hence, it saves time and resources for your company.
- Reproducibility: It helps to ensure that the model-building process is repeatable and consistent for reproducing results and building reliable models.
- Scalability: ML pipelines can be designed to scale to larger datasets and can be incorporated into production systems.
- Quality: ML pipelines ensure that the model-building process is thorough and rigorous to improve the quality of the final model.
- Collaboration: ML pipelines can be shared and used by multiple team members, facilitating collaboration and improving the efficiency of the final ML model.
However, there are several things that you need to take care of while working with Machine Learning pipelines. Else, it can negatively impact the performance and reliability of the model.
Avoid these Ten Pitfalls while Working with ML Pipelines
Here I go over the ten most common pitfalls that you must avoid!
-
Lack of Structured Data
Machine Learning models rely on high-quality and structured data to make accurate predictions. Poorly structured data or dirty data negatively impact ML models.
Solution: To address this issue, fill in missing values, remove outliers, and standardize data formats to clean and structure the data.
-
Lack of Feature Engineering
Feature engineering is the process of selecting and creating relevant features from raw data to train ML models. If features are not carefully selected and engineered, it negatively impacts ML models.
Solution: Create new features through feature extraction or feature construction and eliminate redundant or irrelevant features. Selecting relevant features from the raw data improves model performance.
-
Overfitting
When a model is trained too well on the training data only and is not able to generalize well-unseen data, overfitting occurs. Usually, it happens when the model is too complex, or when there is a need for more data to learn from.
Solution: You can solve the problem in one of the following ways:
- Reducing the complexity of the ML model.
- Increase the amount of training data
- Use regularization techniques. You can do it by adding a penalty for complex models or using dropout to prevent the model from overfitting.
-
Underfitting
If a model is not able to capture the underlying patterns in the data, Underfitting occurs. The models fail to perform well on both the training and test sets. It usually happens by a lack of model complexity or, by lack of sufficient data to learn from.
Solution: You can solve the problem in one of the following ways:
- Use more powerful models and increase the number of parameters.
- Increase the amount of training data
- Use feature engineering and data augmentation
-
Poor Evaluation Metrics
Choosing the right evaluation metric is important to ensure that the ML model meets the desired output. The wrong metric used leads to misleading results and poor model performance.
Solution: Consider the characteristics of the data to choose the right evaluating metrics.
-
Insufficient Training Data
ML models can only make accurate predictions if a sufficient amount of data is fed. If there is insufficient data, they won’t learn effectively and will likely perform poorly.
Solution: You can solve the problem in one of the following ways:
- Use data augmentation or synthetic data generation to increase the training dataset.
- Use transfer learning that involves using a pre-trained model and fine-tuning it as per your specific task.
-
Lack of Hyperparameter Tuning
Hyperparameters are the settings to control the behavior of an ML model. Improper hyperparameter tuning leads to poor ML model functions.
Solution: Use techniques such as grid search or random search that systematically tune the hyperparameters of the model. Here the ML model is trained with different combinations of hyperparameters and finally selects the combination that yields the best performance.
-
Lack of Model Interpretability
ML models need to be interpretable. If the model isn’t, it gets difficult to understand predictions and hence becomes unreliable.
Solution: To address this problem, use LIME (Local Interpretable Model-agnostic Explanations) or SHAP (SHapley Additive explanations) techniques to generate explanations for individual predictions that are made by the ML model. You can also use feature selection or feature importance techniques.
-
Improper Maintenance
Poor model maintenance leads to inaccurate and irrelevant predictions. A regular schedule for retraining and updating the model is important to ensure that ML models remain accurate.
Solution: Timely perform an error analysis to identify any issues that need to be addressed in your ML model.
-
Poor Testing Models
A thorough test of the ML model before deploying it into production is important. If the model is not thoroughly tested, it leads to incorrect predictions.
Solution: Hold different types of test data, such as holdout sets, cross-validation sets, and test sets, to ensure that the model is robust and reliable.
Build With Ksolves
Ksolves offers services to build, manage, and operate robust Machine Learning pipelines. We talk first with clients to understand their needs. We define success metrics as per the input data and then proceed with the development model.
With our 400+ accredited engineers and 24*7 extended tech support, We offer the best tech solutions to your business. Connect us at sales@ksolves.com or call us directly at +91 8130704295 for AIML & Big Data analytics services.
Conclusion
The overarching purpose of a pipeline is to streamline processes in Big data analytics and Machine Learning. It makes building models more efficient and simplified, cutting out redundant work.
![]()





AUTHOR
AI
Mayank Shukla, a seasoned Technical Project Manager at Ksolves with 8+ years of experience, specializes in AI/ML and Generative AI technologies. With a robust foundation in software development, he leads innovative projects that redefine technology solutions, blending expertise in AI to create scalable, user-focused products.
Share with