Understanding Convolution Neural Network (CNN) Architecture – Deep Learning
AI
5 MIN READ
February 1, 2023
![]()

In deep learning architectures, Convnets/CNNs/ is one of the main architectures used to perform image classifications. Image segmentation, face detection, real-time object detection etc. are other important use-cases where CNN architectures are majorly used.
This blog covers image classification – meaning a CNN model sequentially identifies patterns, processes images and provides certain output categories (Eg., Plane, Car, Truck, Bike etc.). An input image is given to the CNN model and model sees this image as an array of pixels. Depending upon image resolution, model will look for w*h*d (here w, h, d depict image width, height and depth respectively). For instance, input image of 10*5*3 array of RGB matrix (3 refers to image depth, RGB values).Below figure depicts the same. A gray scale image is depicted by 4*4*1.
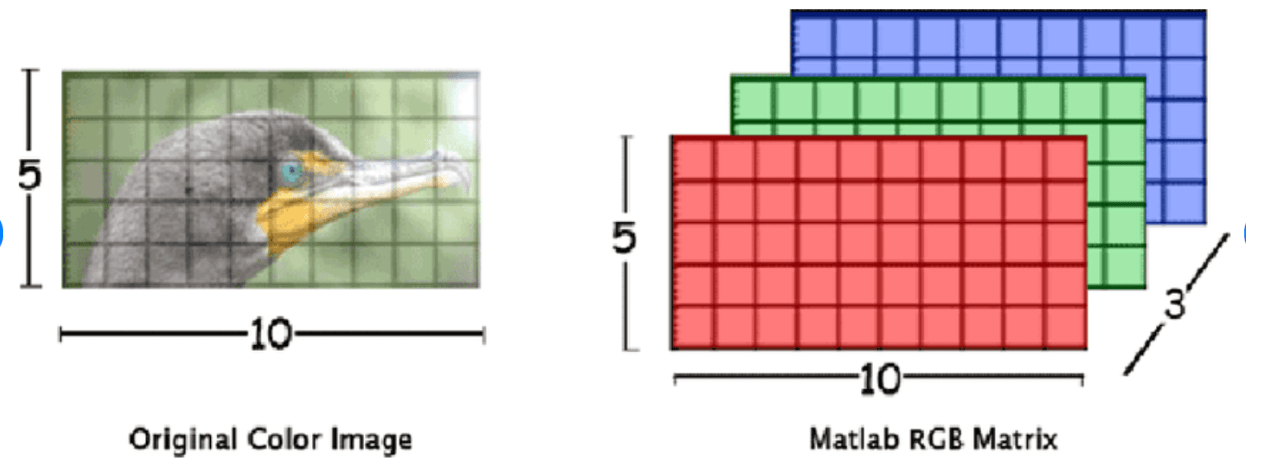
Source:https://www.researchgate.net/figure/Color-image-representation-and-RGB-matrix_fig15_282798184
Image data is technically divided into train and test segments. In the CNN model, each input image will be sequentially processed through a series of convolution layers along with unique kernels (filters), Activation functions, Pooling and Fully Connected Layers (FCC). In the end, Softmax cost function is applied to classify an object class with probability values lying between 0 and 1. The figure below depicts CNN model architecture.
Fig 2: CNN Model Architecture
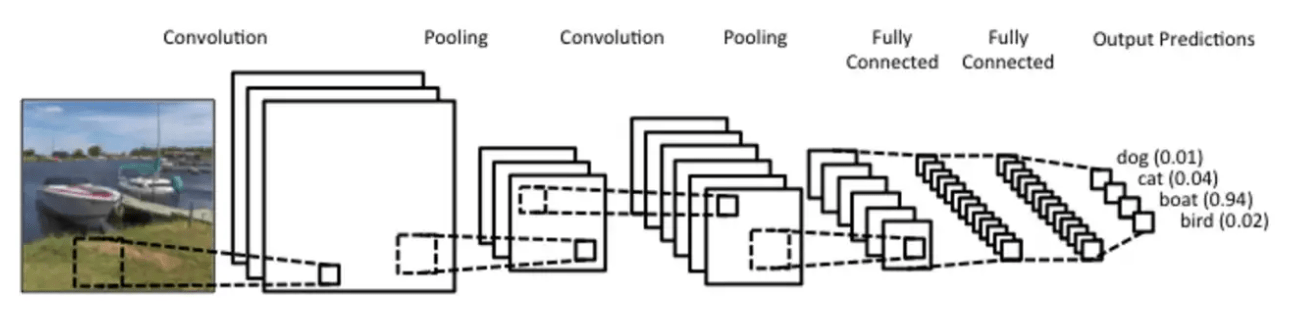
Source: https://medium.com/@Aj.Cheng/convolutional-neural-network-d9f69e473feb
Convolution Layer
This layer is the first layer to extract unique patterns (features) from an input image. It is a mathematical operation where an image matrix and a filter (also called a kernel) is given as two inputs.
Fig 3: An Image Matrix multiplied with kernel

Source:https://medium.com/@RaghavPrabhu/understanding-of-convolutional-neural-network-cnn-deep-learning-99760835f148
Model selects random filters to perform convolution. Every filter tries to find unique features from the input image like edges, lines, circular patterns etc. The output from the convolution is called as feature maps.

Filters (to be learned) Feature Map
Source: https://stackoverflow.com/questions/36243536/what-is-the-number-of-filter-in-cnn
Strides
How much pixel shifts over an input image is called a stride. When stride = 1, then every filter moves 1 pixel at a time. When Stride = 2, then every filter moves 2 pixels at a time and so on
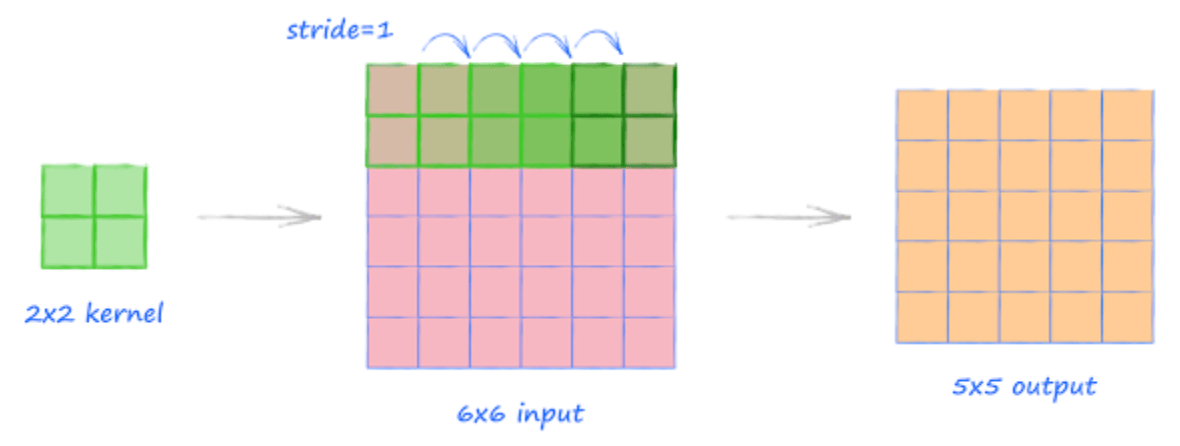
Source:http://makeyourownneuralnetwork.blogspot.com/2020/02/calculating-output-size-of-convolutions.html
Padding
Sometimes, different filters do not fit perfectly on the input image. There are two options can be performed:
- Fill the picture with zeros (called – “zero padding”)
- Drop an image part where the filter is not fitting – also called “valid padding” (keeps only required/valid part)
Non Linearity (ReLU)
ReLU – Rectified Linear Unit is responsible for non-linear operation,output of ReLU is f(x) = max(0,x). The use of ReLU activation function between the convolution layers plays an important role in non-linearity in the convolution architecture. In the real world data needs convolution architecture to learn non-negative linear values from the image dataset. However, ReLU has certain limitations. It can lead to dying ReLU problem – meaning a neuron dies as it is always in the “off” state during back-propagation. As a result, all of the neurons that were never activated will not contribute to the CNN model’s learning process. Therefore, most engineers prefer LeakyReLu over ReLU. Figure below depicts state-of-the-art activation functions.
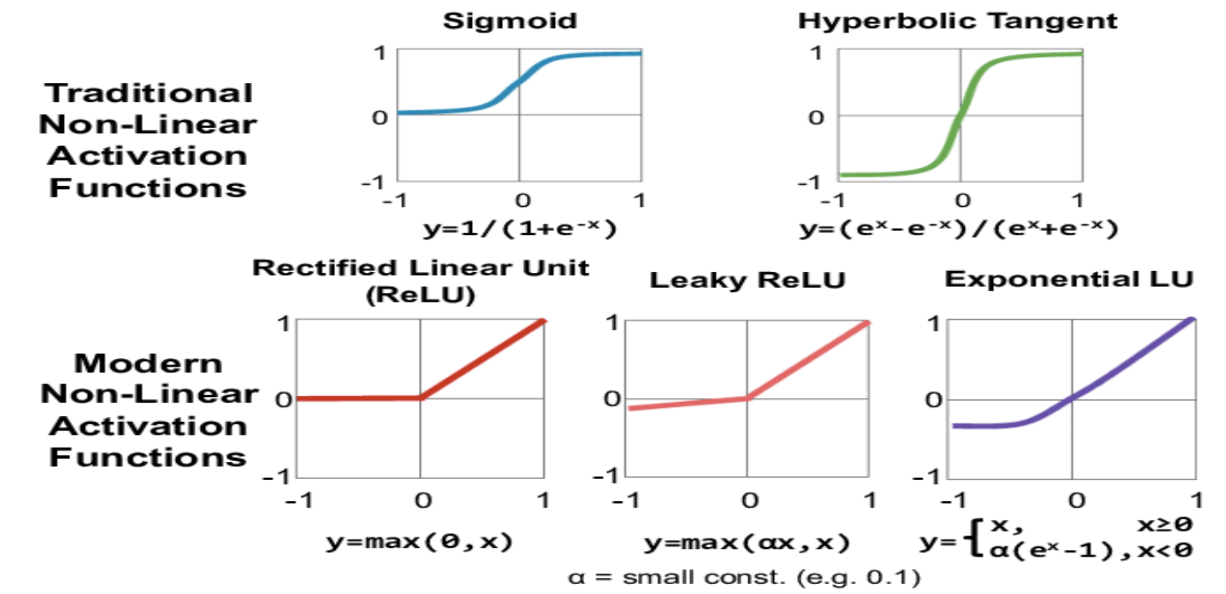
Source:hhttps://www.researchgate.net/figure/Various-forms-of-non-linear-activation-functions-Figure-adopted-from-Caffe-Tutorial_fig3_315667264
Pooling
Pooling reduces image dimensions when images are too large. Spatial pooling (known as sub-sampling) reduces image dimensions while retaining the most unique/important features of an image. It can be of different types:
- Max Pooling
- Average Pooling
- Sum Pooling
Max pooling is performed to reduce overfitting by providing an abstracted representation. Most importantly, it reduces computational cost by considering the largest element from the feature map. The largest element is also considered when performing average pooling.If we sum all elements in the feature map, it is called sum pooling.

Source: https://www.superdatascience.com/blogs/convolutional-neural-networks-cnn-step-2-max-pooling
Fully Connected Layers (FCC)
FCC layers are also called hidden layers. These are sequential layers, which include:
First FCC layer – It takes input from previous feature map matrix, “flattens” them to convert them into a single vector. Every element of the FCC is assigned with a weight to predict the correct labels in the output FCC layer.
FCC output layer – It displays outputs’ final probabilities for each output class label. Activation functions such as softmax or sigmoid are applied which bring probability ranges between 0 and 1 to classify the output class – Plane, Car, Truck, Bike etc. Figure below shows the snippet of FCC layers
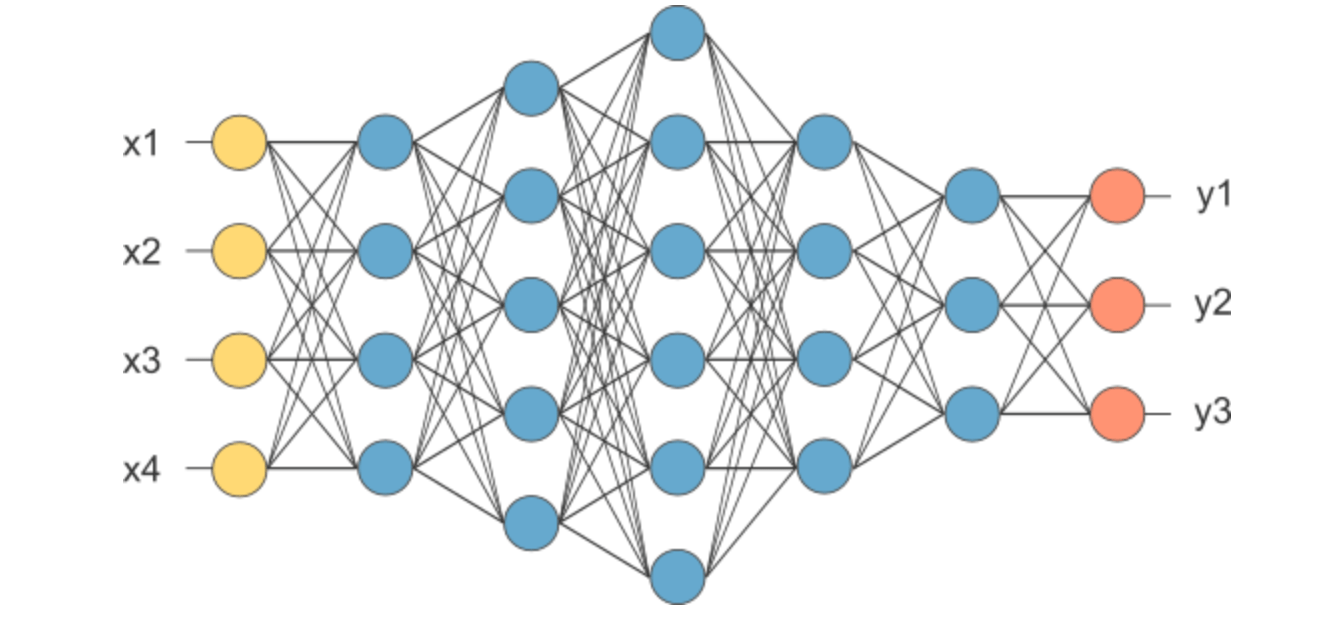
Source:https://medium.com/@RaghavPrabhu/understanding-of-convolutional-neural-network-cnn-deep-learning-99760835f148
Summary
- Give an input image to the convolution layer.
- Choose different parameters, keep filters with strides, use padding if required.
- Apply convolution on the input image and use relevant activation functions (ReLU, Leaky ReLU, etc.)
- Apply pooling to reduce image dimensions by capturing the most important features.
- Use multiple combinations of convolution layers until you get satisfactory feature maps
- Flatten the output feature map from convolution layer and feed it into the fully connected layer (FCC)
- Output the class by applying a relevant activation function (Softmax, Logistic Regression with a cost function) and classify images (output class).
We hope that this article has given you a clear understanding of the CNN architecture Neural Network (CNN) Architecture – Deep Learning Concept. Ksolves is one of the leading software development companies, supported by a highly experienced and skilled team of AI developers to deliver the best services to their global clients.
![]()
Frequently Asked Questions











AUTHOR
AI
Mayank Shukla, a seasoned Technical Project Manager at Ksolves with 8+ years of experience, specializes in AI/ML and Generative AI technologies. With a robust foundation in software development, he leads innovative projects that redefine technology solutions, blending expertise in AI to create scalable, user-focused products.
Share with