How to Achieve High Availability for Apache Kafka
Apache Kafka
5 MIN READ
August 2, 2024
![]()

Achieving Apache Kafka high availability is crucial for ensuring continuous data processing in distributed systems. The problem lies in potential single points of failure, leading to service interruptions and data loss.
But the question that arises is why there is such high availability in Kafka. High availability in Kafka is essential due to the vulnerability of a single cluster. Relying on a lone Kafka cluster exposes the entire system to a single point of failure, impacting a wide array of services within the architecture.
By implementing strategies like replication, partitioning, and failover mechanisms, organizations can enhance Kafka’s resilience. These methods distribute workload across clusters, maintain data consistency, and enable seamless recovery from node failures, ensuring uninterrupted operation and reliable data streams.
This is not it, let’s delve into the write-up and know more about it.
Understanding Kafka Replication
In Kafka, replication stands as a cornerstone feature, ensuring uninterrupted service amid node failures within a cluster. For each topic, a replication factor is set, dictating the number of data copies across the cluster. Increasing this factor improves fault tolerance but requires more resources. These replication strategies for Kafka high availability are pivotal.
Defining High Availability Setup for Apache Kafka for Your Organization
To ensure Kafka Cluster reliability, maintaining availability is important, depending on size and fault tolerance. While Kafka excels at managing vast data volumes for big data challenges, its relevance extends to scenarios with moderate data loads, like IoT and social media, where data grows rapidly and could strain systems.
To achieve high availability, it is important to understand the Kafka’s components . A Kafka cluster comprises a control plane and a data plane, each with distinct roles for seamless data transfer.
1. Control plane tasks include:
- Monitoring server status
- Adapting to server failures
- Managing metadata
2. Data plane responsibilities involve:
- Handling record requests
- Responding to metadata changes
Traditionally, Kafka relied on Apache ZooKeeper for control plane functions, ensuring consistent cluster metadata storage. ZooKeeper designates a Kafka broker as a controller, managing cluster state amidst broker failures or restarts.
How to set up high availability in Apache Kafka
Setting up Apache Kafka high availability is vital for ensuring uninterrupted data processing. Follow these steps to establish a resilient Kafka environment:
1. Cluster Configuration:
- Start by setting up a Kafka cluster with multiple broker nodes distributed across different machines or data centers.
- Configure each broker with identical Kafka settings and ensure they can communicate with each other.
2. Replication Configuration:
- You have to define a replication factor for each topic, specifying the number of replicas (copies) of each partition to maintain across the cluster.
- This replication ensures that data remains available even if some broker nodes fail.
3. Partition Assignment:
- Use the partition assignment strategy of Kafka to distribute partitions evenly across broker nodes.
- Balancing partition assignments helps distribute the workload and prevents individual brokers from becoming overloaded.
4. Monitoring and Alerting:
- Implement robust monitoring tools to track the health and performance of Kafka brokers, partitions, and overall clusters.
- Set up alerts to notify administrators of any anomalies or potential issues, allowing for proactive management and quick resolution.
5. Fault Tolerance:
- Configure Kafka to automatically detect and recover from broker failures by electing a new leader for affected partitions.
- Enable features like ISR (In-Sync Replicas) to ensure that replicas stay in sync with the leader, minimizing data loss during failover.
6. Data Backup and Recovery:
- Implement regular backups of Kafka data, either through built-in tools or third-party solutions.
- Establish procedures for restoring data in case of catastrophic failures or data corruption events.
7. Security Considerations:
- Secure Kafka clusters by implementing authentication, encryption, and access control mechanisms to protect against unauthorized access and data breaches.
- Regularly update security configurations to address emerging threats and vulnerabilities.
8. Scalability Planning:
- Plan for future scalability by designing Kafka clusters with additional capacity to accommodate growing data volumes and increased workload demands.
- Monitor cluster performance over time and adjust resources as needed to maintain optimal performance.
By following these steps and best practices, organizations can establish a highly available Apache Kafka environment capable of meeting the demands of modern data-intensive applications.
Also Read: Read More: Conquering Latency: How Kafka Enables Real-Time Decision-Making
Importance of Redundancy in Kafka Clusters
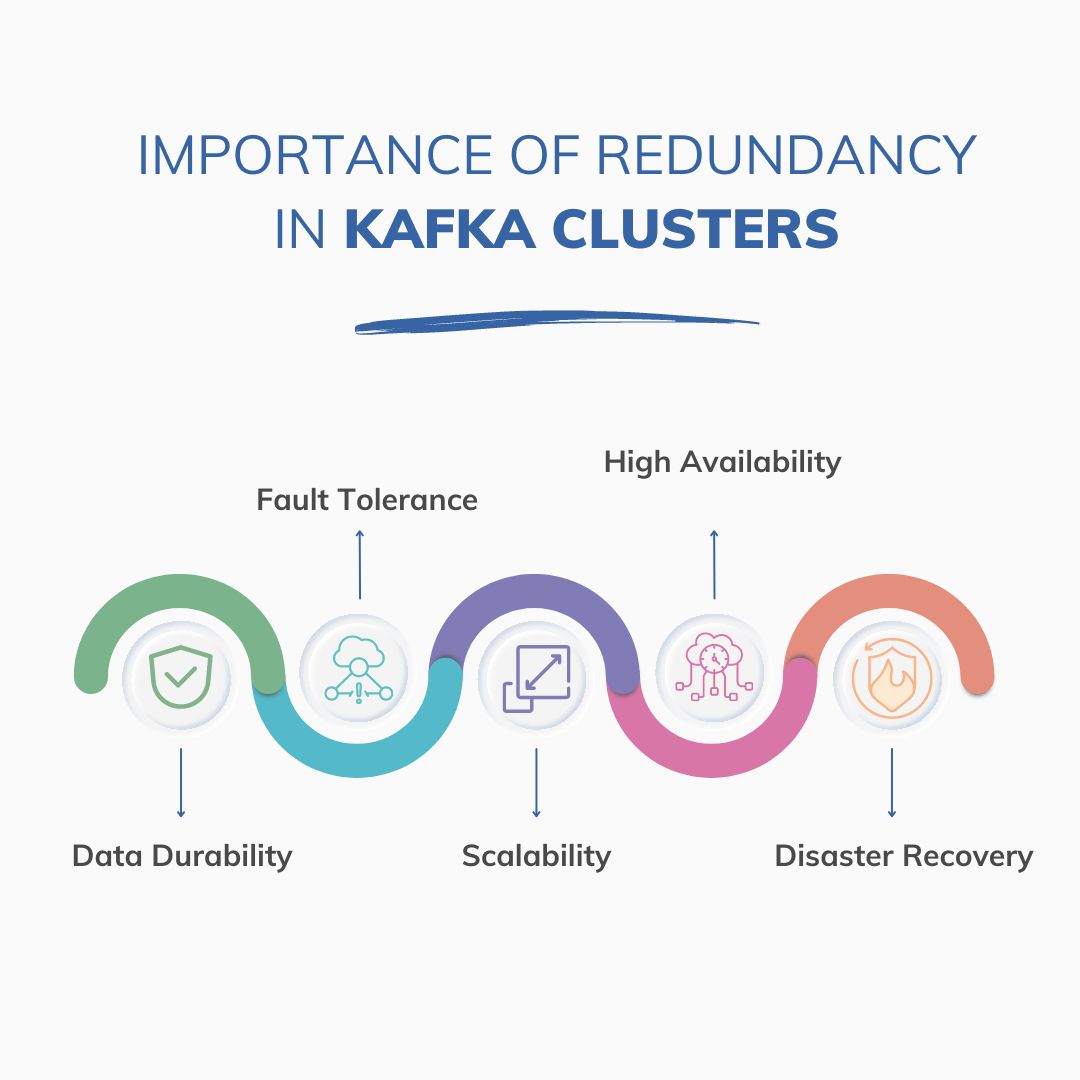
Redundancy is critical in ensuring the reliability and resilience of Kafka clusters. Here’s why redundancy is essential:
Fault Tolerance
This redundancy mitigates the impact of hardware failures, network issues, or software bugs by providing backup resources. In Kafka, redundancy is achieved through data replication across multiple broker nodes. If one broker fails, Kafka can continue serving data from the replicas, ensuring uninterrupted service.
Data Durability
Replicating data across multiple brokers ensures durability and prevents data loss. Even if one or more brokers become unavailable, Kafka can maintain data availability by fetching data from the replicas. This is crucial for maintaining data integrity and meeting reliability requirements.
High Availability
It contributes to high availability by minimizing downtime and service disruptions. With replicated data spread across multiple brokers, Kafka can continue operating even if individual brokers or entire data centers experience failures. This ensures that Kafka clusters remain accessible and responsive to client requests.
Scalability
It also facilitates horizontal scalability by distributing data processing and storage across multiple broker nodes. As data volumes and workload demands increase, additional brokers can be added to the cluster to handle the load. Redundancy allows Kafka clusters to scale out without sacrificing reliability or performance.
Disaster Recovery
Redundancy enables effective disaster recovery strategies by maintaining copies of data in geographically distributed locations. In the event of a catastrophic failure or data center outage, Kafka clusters can fail over to secondary sites or backup clusters, ensuring business continuity and minimizing data loss.
Conclusion
In conclusion, achieving high availability for Apache Kafka is paramount for ensuring uninterrupted data processing. By implementing replication, fault tolerance mechanisms, and disaster recovery strategies, organizations can build resilient Kafka clusters capable of withstanding failures and maintaining data integrity.
For expert assistance in Apache Kafka development services, including high-availability solutions, contact Ksolves experts today. Ensure seamless data flow with our specialized expertise.
![]()











AUTHOR
Apache Kafka
Atul Khanduri, a seasoned Associate Technical Head at Ksolves India Ltd., has 12+ years of expertise in Big Data, Data Engineering, and DevOps. Skilled in Java, Python, Kubernetes, and cloud platforms (AWS, Azure, GCP), he specializes in scalable data solutions and enterprise architectures.
Share with