How to Choose the Right Apache Kafka Cluster Configuration for Your Needs
Apache Kafka
5 MIN READ
December 13, 2024
![]()
Most modern businesses require a reliable platform to manage real-time data feeds. And, if your company uses Apache Kafka, you’re using a reliable distributed event source and stream-processing platform.
Apache Kafka is a popular platform. It’s a distributed publish-subscribe system that ensures proper decoupling among data producers and consumers. It also instills scalability by keeping high throughput and low latency.
However, as a business, you must also know how to choose the right Apache Kafka cluster configuration for your needs. And that’s why, in this article, we’ll learn how to select the proper Apache Kafka Cluster configuration.
Significance of choosing the right Apache kafka Cluster Configuration
Choosing the right Apache Kafka cluster configuration is vital, especially when working with real-time data. For example, if you’re a stock exchange or a bank that deals with real-time data, choosing the proper Apache Kafka Cluster configuration can be the difference between scalable high-throughput or a failed attempt to keep everything synced during demand to store, analyze, and process streaming data. If you’re in doubt, always check out proper Apache Kafka service at KSolves to learn about your options and how you can use Apache Kafka to elevate your business to a new level.
If you pick the right Apache Kafka cluster configuration, you benefit from the following:
- Optimal performance as it ensures low-latency data streaming. You can ensure that Kafka can handle high messages without breaking down by picking the right amount of topic partitions, hardware specifications, and brokers.
- A rightly configured Kafka cluster also makes scalability easy and has the ability to handle data volumes without any bottlenecks.
- Other benefits include better fault tolerance, high availability, improved security, and better cost efficiency.
Understanding Use-Case
Kafka is an open-source solution that is ideal for different use cases. As a business, you must identify a specific use case before choosing the correct Kafka cluster configuration.
For instance, Kafka can be used for messaging and website activity tracking. It is also ideal for log aggregation, steam processing, event sourcing, and commit logs. If your system needs to monitor fraud actively, it can do it with the help of real-time fraud detection with established machine learning models. You can also configure a Kafka cluster to monitor for operational data, aggregating data from different distributed systems to centralized data feeds.
So, teams need to understand their use case before configuring the Kafka cluster. If you’re not able to pinpoint your use case, it’s best to go for Apache Kafka consulting.
Also read, Why and Where You Can Use Apache Kafka.
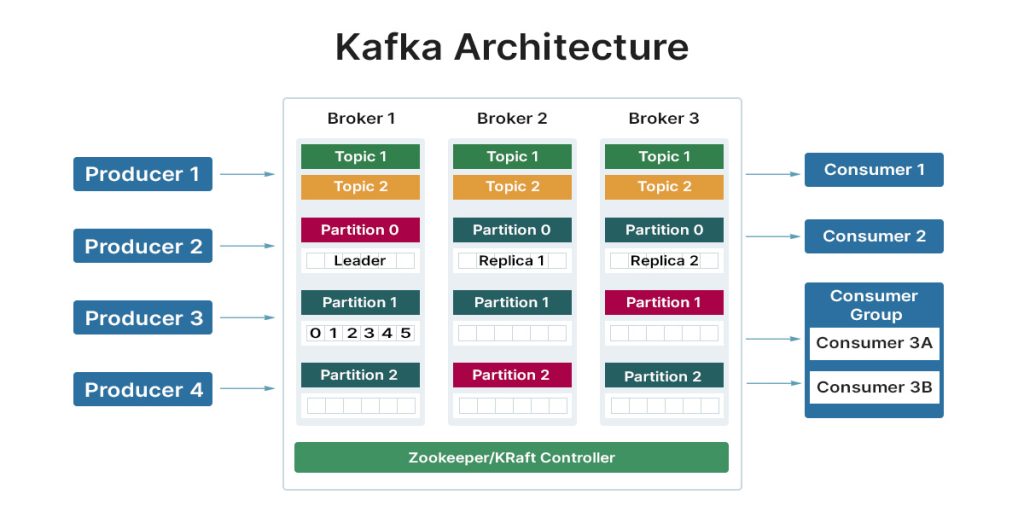
What is Kafka Cluster? How does it work?
Choosing the right Apache Kafka cluster configuration requires a complete understanding of the Kafka cluster. This section will examine the Kafka cluster, its components, and how it works.
A Kafka Cluster is best defined as collecting multiple brokers (servers) working as a distributed system to manage and process data streams. By using multiple servers, Kafka Clusters ensure minimal to no downtime. They are also highly scalable and have real-time data feeds.
Technically, a Kafka Cluster comprises of the following components:
- Brokers: Brokers are servers responsible for the Topic’s Message Storage. A cluster comprises multiple servers to ensure load balancing. Also, these servers are stateless and require Zookeepers to preserve the Kafka Cluster’s state.
- Topics: Topics are used to arrange Kafka records. It is a collection of messages with a common feed or category name.
- Partitions: Topics are divided into logically sequenced, customizable segmented sections.
- Zookeeper: ZooKeeper is a Master Management node that ensures that other Kakfa cluster components work as intended.
- Producers: A producer sends data/messages. It can also publish data within a Kafka cluster.
- Consumers: Lastly, we have consumers that read or consume the Kafka Cluster messages.
All these components work together to ensure optimal data distribution. Replicas and partitions handle the data distribution in Kafka. Moreover, Kafka excels at fault tolerance by providing replication, data retention, automatic failover, and in-sync replicas.
Apache Kafka recently launched KRaft, an evolution over the current version. It removes the need to use ZooKeeper to do metadata management, which in turn, simplifies the Kafka architecture. The KRaft consensus protocol uses the new quorum controller. This brings multiple benefits including ability to enable right-sized clusters, better stability, and an improved single security model. It also gives developers the ability to use Kafka as a single-process way, providing a lightweight platform.
Kafka has currently deprecated Zookeeper and it’ll be removed in v5.
Read more about KRaft here: KRaft – Apache Kafka Without ZooKeeper.
Taking Advantage of Kafka Cluster Configuration Options
Kafka Cluster improves on single node setup by providing better reliability and availability. To achieve the desired scalability, performance, and fault tolerance, you must decide on the number of brokers you’ll need in your Kafka Cluster.

Brokers Required
Starting with minimal brokers is ideal as a business, as you can always scale them up as your needs grow. However, if your company needs high fault tolerance and better parallelism, starting with a decent amount of brokers in your Kafka Cluster is best.
Before you decide on the broker node, you need to consider the broker node with and without ZooKeeper (KRaft mode).
With ZooKeeper enabled, the broker node selection requires you to consider multiple factors, including:
- Quorum consensus deals with the minimum number of server nodes. There’s no minimum broker requirement. However, any update done to the ZooKeeper tree by clients needs to be persistent for successful transactions.
- Having an odd number of machines in the ZooKeeper ensemble is recommended to achieve consensus. You can use the Q = 2N +1 formula, where Q stands for the number of nodes, and N is the number of allowed failed nodes.
- Maintaining an odd Broker count in a Kafka cluster is advisable to remove inconsistency when selecting a Leader. For example, if you have 2 nodes cluster and the connection between them is lost, both will try to act as a leader. So, to ensure a majority quorum for leader election and coordination, you’ll need to select an odd number of nodes.
- For fault tolerance, you’ll need to rely on node redundancy. If a node fails, the ZooKeeper will elect a leader for each partition – ensuring normal operation for the leftover brokers.
In case of no ZooKeeper, i.e., KRaft mode, you’ll need to consider the consensus protocol that works internally. In KRaft mode, the broker node count depends on the following:
- KRaft doesn’t require ZooKeeper so the Kafka cluster can work with just one broker node. This gives flexibility to the development team as it can work on minor requirements without adding at least three broker nodes.
- KRaft mode also improves deployment, thanks to the one architecture that doesn’t depend on external resources.
- KRaft mode also makes it possible to scale as needed.
If you want to move from the older ZooKeeper mode to KRaft, you can easily do it. All you need to do is to upgrade brokers and change the Kafka cluster configuration.
Choosing the right broker node depends on the Kafka version, which means the availability of ZooKeeper or KRaft mode.
Space Requirements
The number of brokers will also dictate the amount of disk space you’ll need to retain messages. For example, if each broker has 10 TB of space, and you need 100 TB of space, then you’ll need ten brokers. Moreover, you’ll also need to select the space based on the messages retention policy (set to a week by default).
The best way to calculate the required space is to multiply the write data speed by the data retention time and replication factor.
Amount of data required = write data speed x time for data retention x replication factor (can be 3 or more).
Next, you’ll need to calculate the throughput based on peak load. It’ll help you understand your project’s CPU, memory, and network requirements.
Topic Configuration
For topic configuration, you’ll need to look at replication factor, retention, and partition. The retention determines how long the data is kept, whereas the replication factor is the number of copies you want to keep.
Next, you’ll need to determine the number of partitions per topic. It is best to set the partition number correctly from the start, as changing them later can be time-consuming and complex.
For partition count/topics, you’ll need to take into account the following:
- Choosing more partitions will lead to higher throughput, which equals parallelism in Kafka.
- However, if you choose more partitions, it’ll also mean more file handles. If you prefer higher partitions, you must handle them in configuration.
- Other side-effects of more partitions include increased end-to-end latency and increased memory usage in the client. It can also lead to more unavailability.
To read more about selecting partition count, read How to Choose the Number of Topics/Partitions in a Kafka Cluster.
Next, we have a replication count, which needs to be at least 2 with a maximum of 4. According to Kafka documentation, the recommended value is 3, which balances fault tolerance and performance.
Producer and Consumer Configuration
It is important to set up producers and consumers to set up the Kafka Cluster properly. For producers, you’ll need to set options such as acknowledgments, batch size, compression type, etc. Similarly, the Consumers option requires you to set up auto-commit intervals, group management settings, and fetch settings.
Factors to Consider When Choosing a Kafka Cluster Configuration
Workload Requirements
- Data Volume: Estimate the daily or hourly data volume to determine the number of brokers and partitions needed.
- Throughput: Assess the required data ingestion and consumption rate.
- Message Retention: Decide how long messages need to be stored, which impacts disk space.
Hardware Configuration
- Storage: Use high-performance SSDs for faster disk I/O.
- CPU: Opt for multi-core processors to handle high message rates.
- Memory (RAM): Allocate sufficient RAM to cache active data and metadata, reducing disk access.
- Network: Ensure high-speed, low-latency network connections between brokers.
Cluster Size and Scaling
- Vertical Scaling: Increase the resources (CPU, RAM, storage) of individual brokers. Suitable for small to medium workloads but limited by hardware capacity.
- Horizontal Scaling: Add more brokers to distribute the load across multiple servers. This approach provides better fault tolerance and higher throughput but requires careful partition management and synchronization.
Trends in Apache Kafka Cluster Configuration
- Cloud-Native Deployments: More organizations are deploying Kafka on cloud platforms such as AWS MSK, Azure Event Hubs, or Google Cloud Pub/Sub for easier scaling and managed services.
- KRaft Mode: Kafka’s new mode eliminates the need for ZooKeeper, simplifying cluster management and reducing operational complexity.
- Integration with Kubernetes: Deploying Kafka on Kubernetes offers automated scaling, self-healing, and seamless integration with other cloud-native tools.
Why Choose Ksolves For Apache Kafka Consulting Services?
Ksolves Apache Kafka Consulting Services provides customized solutions for scalable, secure, and high-performance data streaming. With 12+ years of expertise, we are here to ensure instant Kafka deployment, integration, and optimization across cloud and on-premise environments. The industry expertise, proactive monitoring, and 24/7 support help businesses maximize Kafka’s potential to ensure minimal downtime and robust data security.
Conclusion
Choosing the right Apache Kafka Cluster requires time. It needs a complete understanding of your project requirements and a deep understanding of how Apache Kafka works under the hood. It is essential to follow the best practices to get the best results. And, if you’re unsure how to approach, you can always contact Ksolves for complete Apache Kafka service with proper Apache Kafka consultation, implementation, integration, and deployment.
![]()











AUTHOR
Apache Kafka
Atul Khanduri, a seasoned Associate Technical Head at Ksolves India Ltd., has 12+ years of expertise in Big Data, Data Engineering, and DevOps. Skilled in Java, Python, Kubernetes, and cloud platforms (AWS, Azure, GCP), he specializes in scalable data solutions and enterprise architectures.
Share with