Why and Where You Can Use Apache Kafka
Apache Kafka
5 MIN READ
August 26, 2022
![]()

Over the last few years, Apache Kafka has gained a lot of popularity and hence been adopted by many companies in their tech stacks. What developers cherish most about this technology is its high throughput processing power and scalability. Moreover, It supports high-performance and a publish-subscribe mechanism.
If you want to know more about Apache Kafka and how it can suit your business, we have a detailed blog here. Continue reading to explore!
What is Apache Kafka?
Apache Kafka is an open-source distributed event streaming platform that thousands of businesses use for a variety of purposes, for example, high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
The core capabilities of Apache Kafka are:
- High Throughput
Apache Kafka has the capacity to deliver messages across the network with limited throughput using a cluster of machines with latencies as low as two milliseconds. - Scalable
Apache Kafka clusters up to a thousand brokers, trillions of messages every day that includes petabytes of data and hundreds of thousands of partitions. It elastically scales and contracts storage and processing. - High Availability
It can easily stretch clusters (efficiently) over availability zones and also connect separate clusters across different geographic regions.
Why and Where You Can Use Apache Kafka In Your Business?
Because of its fault tolerance/ durability and scalability, Apache Kafka has found its space in Big Data as a reliable platform to ingest (process) and move forward (give desired outputs) large amounts of data quickly and securely.
Apache Kafka offers many applications to the business sector. It is you who can choose the version that suits your business best. From simple message passing (via inter-service communication in microservices architecture) to whole Big Data stream processing platform applications, you can pick your call.
Are you wondering how Apache Kafka works for your business?Here is a detailed discussion of different use cases of Apache Kafka for many different working companies:
Stream Processing:
The most popular use case of Kafka seems to be Stream Processing. Due to its high fault tolerance and distributed attributes, you can build a streaming platform that transforms input Kafka topics into output Kafka topics.
Many users of Kafka process data in processing pipelines consisting of multiple phases:
- Input data consumed from Kafka topics
- Aggregating and enriching or transforming data into new topics (processed) for further consumption or follow-up processing
To better understand the Apache Kafka data streaming service, let us take an example of a processing pipeline for recommending news articles.
- It takes article content from RSS feeds
- Publish it to an “articles” topic
- Further processing might normalize/ deduplicate this content and publish the cleansed article content to a new topic
- The final processing phase recommends this content to users
It is important to note here that such processing pipelines create graphs of real-time data flows based on the individual topics. All of such data processing (as described above) is done with the help of Kafka Streams. These Kafka streams are lightweight but very powerful stream processing libraries available in Apache Kafka to perform data processing.
Messaging/ Message Broker
Apache Kafka works more than well to be a replacement for a traditional Message Broker. Let us explore what a Message Broker is first!
A Message Broker is software that enables different applications/ systems/ services to communicate with each other. That is, message brokers enable different systems to exchange information in the form of messages. Message brokers are popularly used to decouple processing from data producers, buffer unprocessed messages etc.
You can effortlessly use Apache Kafka for messaging different applications because of its better throughput, built-in partitioning, replication, and fault tolerance. Its low end-to-end latency and strong durability guarantee Kafka a good solution for large-scale message processing applications.
[In this domain, you can compare it to RabbitMQ]
Website Activity Tracking
Any business sector can easily use Apache Kafka for website activity tracking. You can use it to track activity data and operational metrics in real-time. Also, you must note that activity tracking is a voluminous task as many activity messages are generated for each user page view (which requires Big Data processing).
- First, Kafka was used to rebuilding a user activity tracking pipeline as a set of real-time publish-subscribe feeds. Site activities like page views, searches, or other actions that website users might have taken were published to central topics with one topic per activity type.
- These feeds then become available for subscription for various use cases, for example, real-time processing, monitoring, and loading into data warehousing systems for processing and reporting.
Metrics Collection and Monitoring
You can easily integrate Kafka with real-time monitoring applications that need Kafka topics.
The process involves:
- Aggregating statistics from distributed applications by Kafka
- Producing centralized feeds of operational data by Kafka
Real-Time Analytics
Apache Kafka can do real-time analytics. It is true because of its ability to process data as soon as they become available. Kafka transmits data from Big Data producers to Big Data handlers and further to Big Data storage.
Log Aggregation
Log aggregation is the process of collecting/ standardizing/ consolidating log data from across an IT environment. It is usually done to facilitate streamlined log analysis. Kafka offers a log aggregation solution too. You can easily aggregate or process logs using Apache Kafka.
Log aggregation typically involves collecting log files of the servers and putting them in a central place for processing; Apache Kafka abstracts away the details of files. It gives a cleaner abstraction of log/ event data as a stream of messages. Hence, it allows for lower-latency processing and easier support for multiple data sources and distributed data consumption.
[If you want to store logs in a Kafka cluster, publish logs into Kafka topics.]
In comparison to log-centric systems, Kafka offers:
- Better performance
- Stronger durability guarantees due to replication
- Lower end-to-end latency
Microservices
Kafka also found an application in microservices. Microservices benefit from Kafka by using it as a centric intermediary letting them communicate with each other.
In Kafka-centric applications, It’s the receiver that decides asynchronously which events to receive, thus offering more reliability and scalability than architectures without Kafka.
IoT (Internet of Things) Data Analysis
Another use case of Kafka seems to be a central location that can send/ read data from IoT devices. Kafka easily scales out or scales in to fulfil peak loads of traffic from different devices.
The MQTT broker is persistent and consumes push data from IOT devices which Kafka Connector later pulls at its own pace. Hence, neither the Kafka Connector gets overwhelmed by the data source nor overwhelms the source.
Kafka works in a real-time scenario. All you need to have is:
- IoT devices that use MQTT(message queuing telemetry transport) system to publish messages
- Configure the MQTT broker to receive messages
- Connect Kafka to the MQTT broker
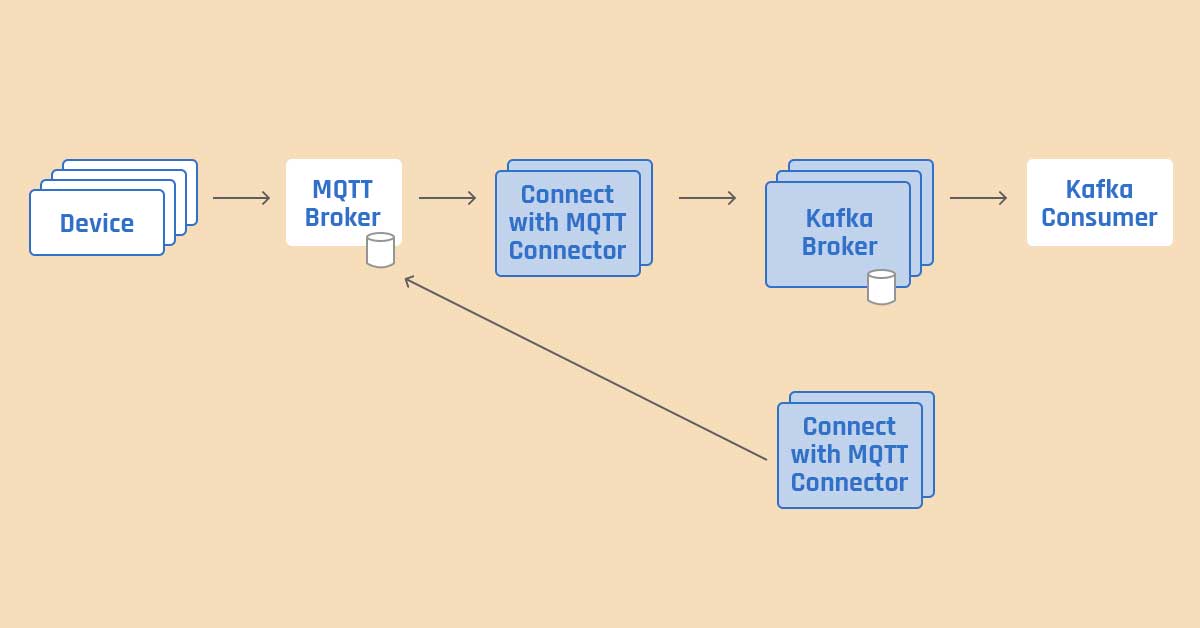
You can use Kafka Connect MQTT or HiveMQ for the connection.
Integrate Kafka To Your Business
The most challenging part of implementation is the development of highly reliable live services that work 24/7 without outages, latencies and failures and provide a great customer experience. Building these types of applications demands special expertise and deep commitment and requires a very different, service-oriented design to which Ksolves is ready to commit.
Ksolves has been for a decade in the Business to serve the Apache Kafka implementation and integration to its customers. Adopt a growth mindset and be curious to explore more with us. Contact us at sales@ksolves.com for Apache Kafka development and support.
Conclusion
Apache Kafka is one of the five most active projects of the Apache Software Foundation and has been trusted by thousands of organisations. From giant internet users to car manufacturers to stock exchanges, it has crossed more than 5 million unique lifetime downloads. You, too, must leverage Its unparalleled abilities to add value to your business.











AUTHOR
Apache Kafka
Atul Khanduri, a seasoned Associate Technical Head at Ksolves India Ltd., has 12+ years of expertise in Big Data, Data Engineering, and DevOps. Skilled in Java, Python, Kubernetes, and cloud platforms (AWS, Azure, GCP), he specializes in scalable data solutions and enterprise architectures.
Share with