Conquering Latency: How Kafka Enables Real-Time Decision-Making
Apache Kafka
5 MIN READ
March 21, 2024
![]()

In this cutting-edge business era, magnetizing the audience is only possible by keeping smart decision-making in the center stage. Having access to real-time data streaming can help you master this art. According to a forecast by Markets and Markets, the size of global data streaming analytics is expected to expand by over $50 billion by the year 2026.
Kafka has emerged as one of the most prominent transformative forces that can help you leverage the full potential of data. It is an open-source distributed streaming platform, that excels at handling massive volume data in a fault-tolerant and scalable manner.
According to a study around 42% of organizations are already using real-time analytics and 32% of the left are planning to move towards it. Here in this blog, we will understand how you can procrastinate latency using Apache Kafka architecture.
What is Real-Time Data Streaming?
Real-time data streaming refers to the continuous and immediate flow of data. Real-time data streaming allows data to be transmitted and analyzed as it is integrated, unlike your traditional batch processing.
According to McKinsey, studies show improved customer satisfaction and operational efficiency with revenue growth after implementing real-time data streaming. It also holds an essential place in various domains like finance, healthcare, and IoT. Timely information is essential to all these places for monitoring, responding to events, and gaining a competitive edge.
Here technologies like Apache Kafka performance for real-time data processing becomes instrumental and provides benefits like scalability, fault-tolerance, and low latency processing.
How does it Work?
Data Generation:
Real-time data streaming begins with the generation of data from various sources, such as sensors, applications, or databases.
Ingestion:
- The data is ingested into a streaming platform, where it is collected and processed in real time.
- Ingestion mechanisms ensure a continuous flow of data into the streaming system.
Partitioning:
- To enhance parallel processing and scalability, the data is often partitioned into smaller subsets.
- Each partition is independently processed, allowing for efficient utilization of resources.
Processing:
- Stream processing engines, analyze and manipulate the data in real time.
- This may involve filtering, aggregating, or transforming the data to extract relevant information.
Event Time Handling:
- Real-time streaming systems are often considered the event time – the time when an event occurred – to ensure accurate and chronological processing, especially in scenarios where events might arrive out of order.
Storage:
- Processed data can be stored for further analysis or archival purposes.
- Some systems may use both in-memory storage for quick access and durable storage for long-term retention.
Event Notification:
- Processed results or events of interest can trigger notifications or actions, allowing timely responses to critical events.
Output and Consumption:
- The final results or processed data are delivered to downstream applications, dashboards, or other systems for consumption.
- This enables real-time monitoring, analytics, and decision-making.
Fault Tolerance:
- Real-time streaming systems often incorporate fault-tolerant mechanisms, ensuring resilience to failures and guaranteeing data integrity even in the face of challenges like node failures or network issues.
Scalability:
- The Apache Kafka architecture and its components are designed to scale horizontally, allowing for the addition of resources to handle increasing data volumes or processing requirements.
Read More: Apache Kafka vs Apache Spark Streaming: Understanding the Key Differences
Apache Kafka: Everything You Need to Know
Apache Kafka is an open-source streamlining platform that is designed to build real-time data pipelines and streaming applications. As the name says it is developed by Apache Software Foundation. It provides a reliable, scalable, and fault-to-tolerant solution for handling a stream of data.
This is well suited for Kafka use cases requiring high throughput, low latency, and durability. These features make Kafka a popular choice for building event-driven architectures.
Apache Kafka Architecture:
Kafka architecture is based on a distributed publish-subscribe model, comprising key components:
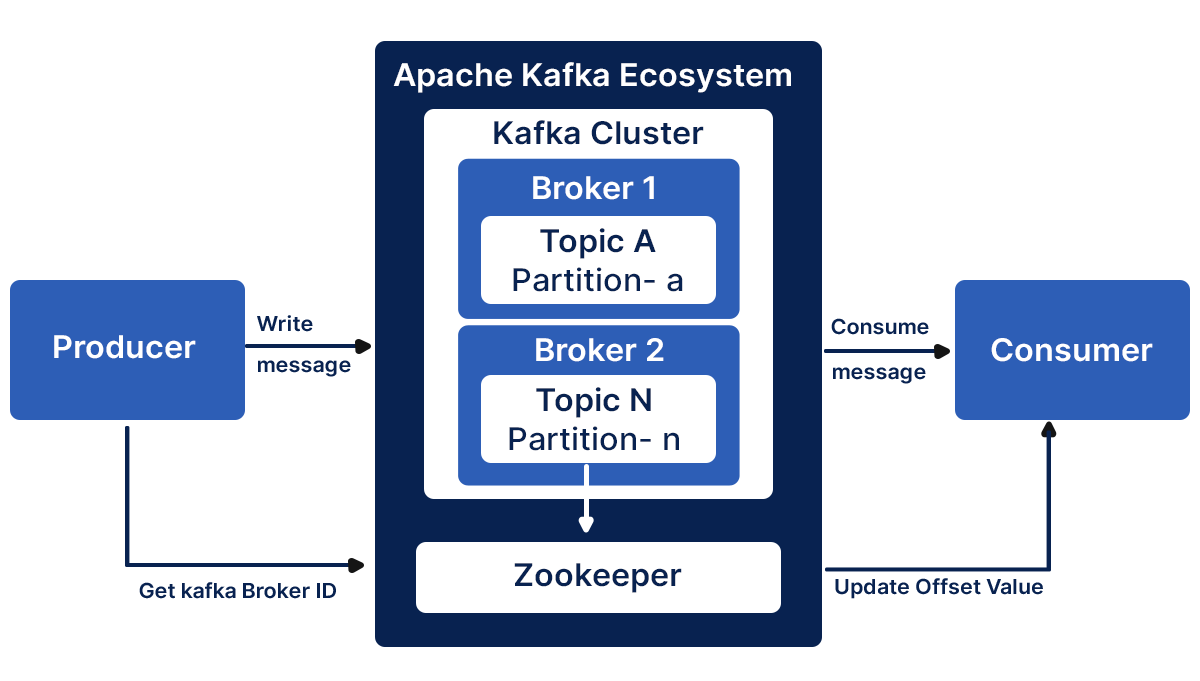
Producers:
- They are responsible for publishing data to Kafka topics.
- They send records (messages) to specific topics, which act as channels for organizing and categorizing data.
Brokers:
- Kafka brokers form the core of the system.
- They are servers responsible for storing and managing the streams of records. Multiple brokers work together to form a Kafka cluster.
Topics:
- Topics represent streams of records in Kafka.
- Producers publish records to topics, and consumers subscribe to topics to receive and process the data.
Partitions:
- These topics are divided into partitions, allowing parallel processing and scalability.
- All these partitions are hosted on a specific broker, and the overall topic’s data is distributed across the partitions.
Consumers:
- Consumers usually subscribe to topics and process the records.
- They can be part of a consumer group, enabling load balancing and fault tolerance.
Zookeeper:
- Zookeeper coordinates and manages the Kafka brokers, helping with tasks such as leader election, configuration management, and synchronization.
Kafka Replication and Partitions:
Replication:
- Kafka ensures fault tolerance through data replication.
- Each partition has one leader and multiple replicas.
- These replicas are hosted on different brokers, ensuring data durability even if some brokers fail.
Partitions:
- These topics are divided into partitions to enable parallel processing.
- All these partitions are an ordered, immutable sequence of records.
- Kafka ensures that records within a partition are written and read in order.
Kafka’s integration with other systems makes it stand out from the rest of the competition. It presents the best results with ConnectAPI, Kafka Streams, and REST Proxy. This was, What is Apache Kafka and how does it work? Further, we will understand how to use Kafka for real-time data streaming.
Real-Time Data Streaming Using Kafka
The Apache Kafka performance for real-time data processing is unmatched. It stands out as a pivotal tool for implementing real-time data streaming solutions.
Here is how Kafka facilitates real-time data streaming: 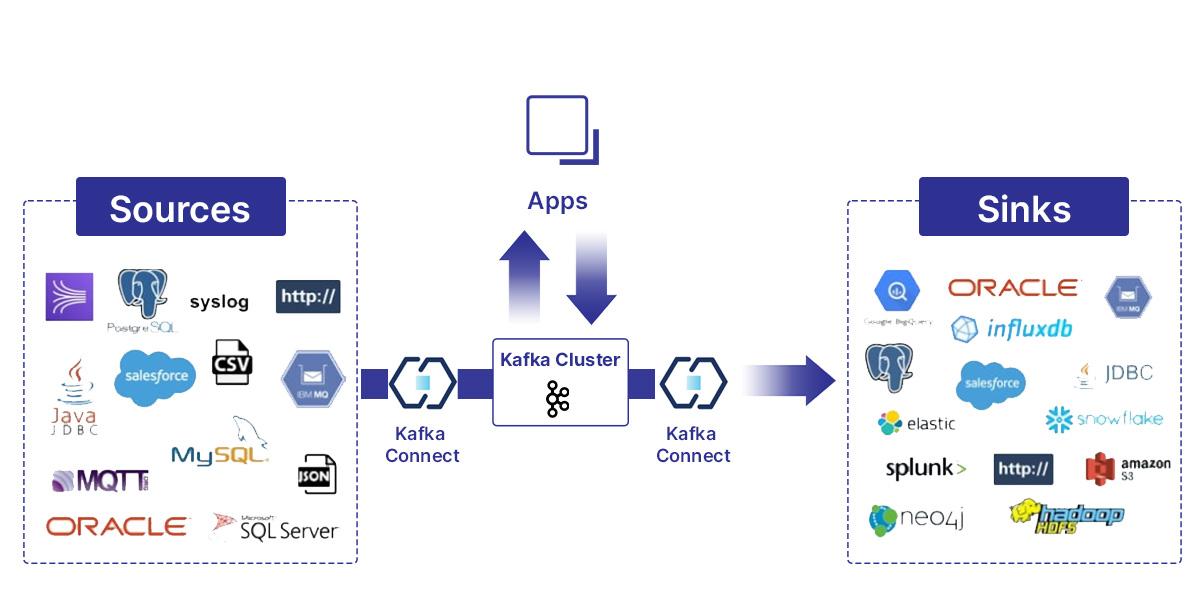
Ingestion of Real-Time Data:
Kafka ensures seamless ingestion of real-time data from diverse sources. It includes sensors, applications, and databases. Producers publish data records to Kafka topics, initiating the flow of information.
Distributed Publish-Subscribe Model:
Kafka employs a distributed publish-subscribe model. Here producers publish records on topics, and consumers subscribe to these topics. This Apache Kafka architecture supports parallel processing and scalability, crucial for handling large volumes of real-time data.
Scalable and Fault-Tolerant Architecture:
Kafka operates on a cluster of brokers, each responsible for managing partitions of data. This distributed architecture ensures scalability, with the ability to add more brokers to handle increased data loads. Additionally, replication of the Kafka mechanism ensures fault tolerance, safeguarding against broker failures.
Partitioning for Parallel Processing:
Topics in Kafka are divided into partitions, allowing for parallel processing of data. Each partition is independently processed, enabling efficient utilization of resources and enhancing overall system performance.
Real-Time Processing with Kafka Streams:
Kafka Streams, a stream processing library built on top of Kafka, empowers developers to build real-time applications. It enables the creation of microservices, analytics, and transformations on the streaming data, unlocking the potential for instantaneous insights.
Read More: Apache Kafka Architecture For Microservices: 5 Advantages
End-to-End Event Processing:
Kafka supports end-to-end event processing, from data generation to consumption. Producers generate events, Kafka brokers store and manage these events, and consumers process and react to them in real-time. This end-to-end flow ensures a seamless and low-latency experience.
Kafka Integration with Other Systems:
Connect API facilitates smooth integration with external systems. Connectors for various databases, storage solutions, and analytics platforms enable the movement of data between Kafka and external technologies.
Reliability and Durability:
Kafka ensures the reliability and durability of data through features like acknowledgments, replication, and persistence. Producers can configure acknowledgment settings to ensure data is successfully delivered to Kafka before moving forward.
Read More: Apache Kafka for Stream Processing: Common Use Cases
Conclusion:
Apache Kafka Implementation can be a game-changing process for your business growth. In today’s data-driven market, it is essential to streamline your data to leverage its full potential.
By efficiently managing data ingestion partitioning and replication, Kafka ensures low latency processing. It allows businesses to respond promptly to changing conditions. However, this integration can be strenuous and most of the businesses suffer because of improper guidance.
The experience of an Apache Kafka Development Company matters a lot. It is a validation of how well the resources can handle the situation and provide you with a fruitful integration.
Ksolves with its 12 years of experience helps you to utilize the best benefits of Apache Kafka for real-time data streaming. We have experienced resources with hands-on expertise in handling Apache Kafka.
We are just a click and phone call away from you. Let real-time data streaming grow your businesses.
Hope this was helpful!
![]()











AUTHOR
Apache Kafka
Atul Khanduri, a seasoned Associate Technical Head at Ksolves India Ltd., has 12+ years of expertise in Big Data, Data Engineering, and DevOps. Skilled in Java, Python, Kubernetes, and cloud platforms (AWS, Azure, GCP), he specializes in scalable data solutions and enterprise architectures.
Share with