Key Components Of Apache Spark Streaming: An Interesting Guide
Big Data
5 MIN READ
March 28, 2025
![]()

Apache Spark Streaming is an extension of the Spark API framework that processes live data streams with high fault handling and throughput. Spark Streaming is still available but Structured Streaming is recommended for new projects. Despite this, Spark Streaming is still popular for data ingestion from diverse sources such as Kafka and Kinesis. It provides a high-level abstraction called DStream for continuous data streaming. Continue reading to explore its core concepts and key components!
How Does Apache Spark Streaming Work?
Apache Spark Streaming is a powerful real-time data processing framework that distributes tasks across a cluster for parallel execution. Here’s how it works step by step:
- Data Ingestion:
- Spark Streaming receives real-time data from sources like Apache Kafka, Flume, Kinesis, or TCP sockets.
- The incoming data stream is divided into small batches (micro-batches) based on the configured batch interval.
- Job Creation & Transformation:
- Each batch is treated as an RDD (Resilient Distributed Dataset), enabling Spark’s distributed processing.
- The transformations (e.g., map, filter, reduceByKey) defined in the Spark Streaming application are applied to these RDDs.
- Task Scheduling:
- The Spark Driver creates a logical execution plan, builds a Directed Acyclic Graph (DAG) from transformations, and then schedules tasks for execution on worker nodes.
- The DAG is divided into smaller tasks, which are then scheduled for execution.
- Task Distribution to Executors:
- The Spark Cluster Manager (YARN, Mesos, or Kubernetes) assigns tasks to worker nodes (executors) in the cluster.
- Each executor runs one or more tasks in parallel, processing different partitions of the data.
- Parallel Processing:
- Executors process their assigned tasks independently, applying the transformations and aggregations defined in the streaming application.
- Data shuffling occurs if needed (e.g., for operations like reduceByKey that require data redistribution).
- Result Generation & Storage:
- The final processed data is collected from different executors.
- The output is sent to external storage or databases such as HDFS, Cassandra, MySQL, or even real-time dashboards.
- Fault Tolerance & Checkpointing:
- If a node fails, Spark’s lineage-based recovery mechanism reconstructs lost data from previous RDDs.
- Checkpointing is used primarily for stateful transformations, whereas stateless operations rely on RDD lineage for recovery.
This distributed processing approach enables Spark Streaming to handle large-scale real-time data efficiently with high fault tolerance and scalability.
Use Cases of Spark Streaming
- Real-time fraud detection in financial transactions: Identifies suspicious activities instantly by analyzing transaction patterns.
- Live monitoring of IoT sensor data: Processes real-time sensor readings to detect anomalies or optimize performance.
- Log analysis for security & anomaly detection: Detects security threats by continuously analyzing system logs.
- Social media sentiment analysis: Tracks and evaluates user sentiments in real-time for brand monitoring.
- Stock market data streaming: Analyzes live stock price movements to support high-frequency trading strategies.
What Are The Key Components Of Spark Streaming
Apache Spark Streaming consists of five main components that perform real-time data processing. Let’s review them here!
-
DStream (Discretized Stream):
It is the fundamental abstraction. A DStream represents a continuous stream of data divided into small batches, processed sequentially. Each DStream is a sequence of RDDs (Resilient Distributed Datasets), the core data structure in Spark.
-
Receiver:
A receiver is responsible for receiving data from external sources like Kafka, Flume, or custom sources and storing it in DStreams. Receivers act as the entry point for streaming data into the Spark system.
-
Transformations:
Transformations are the operations you perform on DStreams. Apache Spark Streaming supports various operations like map(), reduce(), join(), and window(), enabling you to process and manipulate streaming data in real-time.
-
Output Operations:
Once the data is processed, output operations define what happens with the results. You write the processed data to different sinks, such as HDFS, databases, or dashboards to make it available for further analysis.
-
Streaming Context:
It provides the main access point for creating Apache Spark Streaming pipelines. It is responsible for managing the streaming computation, initiating the receivers, and scheduling jobs.
Exploring The Basic Concepts Of Apache Spark Streaming
After covering the key components, let’s learn about the basic concepts of Spark Streaming that cover Apache Spark use cases!
- Linking: In Spark Streaming, linking refers to connecting the streaming engine with data sources such as Kafka or Flume. These connections enable Spark to ingest live data streams seamlessly for processing.
- Transformations on DStreams: You can process and analyze data streams instantly with it. Operations like map and reduce provide powerful ways to process data over time intervals.
- DataFrame and SQL Operations: Apache Spark Streaming enables converting DStreams into DataFrames for structured querying using Spark SQL. This capability bridges the gap between batch and stream processing for advanced analytics.
- MLlib Operations: Spark Streaming seamlessly connects with Spark MLlib to apply machine learning algorithms to real-time data streams. This enables predictive analytics with anomaly detection across dynamic environments.
- Caching / Persistence: Caching or persisting DStreams in memory or disk optimizes Spark Streaming performance by reducing recomputation. This feature is crucial when the same data is used across multiple transformations.
- Checkpointing: Checkpointing provides fault tolerance in Spark Streaming by periodically saving metadata and operational state. It allows the application to recover from failures without starting from scratch.
What Are The Primary Characteristics & Features Of A Spark Stream?
When dealing with Spark Streaming, you must understand the primary characteristics defining a Spark stream. Let’s cover its core features and characteristics, making it one of the most popular real-time data processing platforms!
- Unified Engine: Spark Streaming works on top of the Spark core engine, enabling you to process both batch and streaming data in the same framework.
- Data as Micro-batches: Spark Streaming processes data in micro-batches, where each batch is a small chunk of data collected over a short period. This architecture allows Spark to process real-time data efficiently while maintaining high throughput.
- Processing in Parallel: Spark leverages its distributed computing model, which means that the data within each micro-batch is processed in parallel across the nodes of a Spark cluster, ensuring scalability and performance.
- Fault Tolerance: Apache Spark Streaming provides fault tolerance through its built-in checkpointing mechanism. In case of failure, Spark can recover from the last checkpoint, ensuring that no data is lost during processing.
- High Throughput & Low Latency: Spark Streaming processes real-time data with high throughput and low latency, making it suitable for applications requiring fast responses.
- Windowed Operations: Spark Streaming supports windowed operations, enabling computations over sliding data windows. It is essential for analyzing patterns over time.
Advanced Scaling Strategies in Apache Spark Streaming
Scaling in Apache Spark Streaming ensures high throughput while maintaining low latency. Here’s how it’s achieved:
1. Dynamic Resource Allocation
- Enables automatic scaling by dynamically adding or removing executors based on workload demand.
- Prevents over-provisioning and optimizes resource utilization.
2. Increasing Parallelism
- Adjusting the number of partitions within RDDs helps distribute workloads efficiently across available cluster resources.
- Use repartition() or coalesce() to control partitioning.
3. Load Balancing with Backpressure Handling
- Backpressure prevents overwhelming the system with excessive data.
- Use Spark’s internal backpressure mechanism (spark.streaming.backpressure.enabled=true) to adjust batch processing rates dynamically.
4. Auto-Scaling on Kubernetes
- When running Spark Streaming on Kubernetes, Horizontal Pod Autoscaler (HPA) automatically scales executor pods based on CPU/memory utilization.
Watermarking in Spark Streaming for Late Data Handling
Watermarking is essential for handling late-arriving data in event-time-based processing. It ensures that old events do not affect stateful aggregations. Here’s how it works:
1. Defining Watermark Thresholds
- A watermark defines the acceptable delay for late data before it is discarded.
- Example: df.withWatermark(“timestamp”, “10 minutes”)
2. Using Watermarks with Windowed Aggregations
- Watermarks ensure that computations include late-arriving data only within a certain threshold.
- Example: df.withWatermark(“timestamp”, “10 minutes”)
.groupBy(window(col(“timestamp”), “5 minutes”))
.agg(count(“value”))
- This configuration aggregates data every 5 minutes while allowing late arrivals up to 10 minutes.
Performance Tuning in Apache Spark Streaming
1. Optimizing Batch Interval
- Setting the correct batch interval ensures timely processing without overloading the system.
- Recommended settings:
- Low-latency applications: 500 ms – 1 second
- High-throughput applications: 5–10 seconds
2. Efficient Data Serialization
- Use Kryo serialization instead of Java serialization for faster object serialization:
sparkConf.set(“spark.serializer”, “org.apache.spark.serializer.KryoSerializer”)
3. Enable Speculative Execution
- Helps mitigate slow task execution by running duplicate tasks:
sparkConf.set(“spark.speculation”, “true”)
4. Optimize Shuffle Operations
- Reduce unnecessary shuffling using reduceByKey instead of groupByKey.
- Increase shuffle partitions (spark.sql.shuffle.partitions=200 by default) for large datasets.
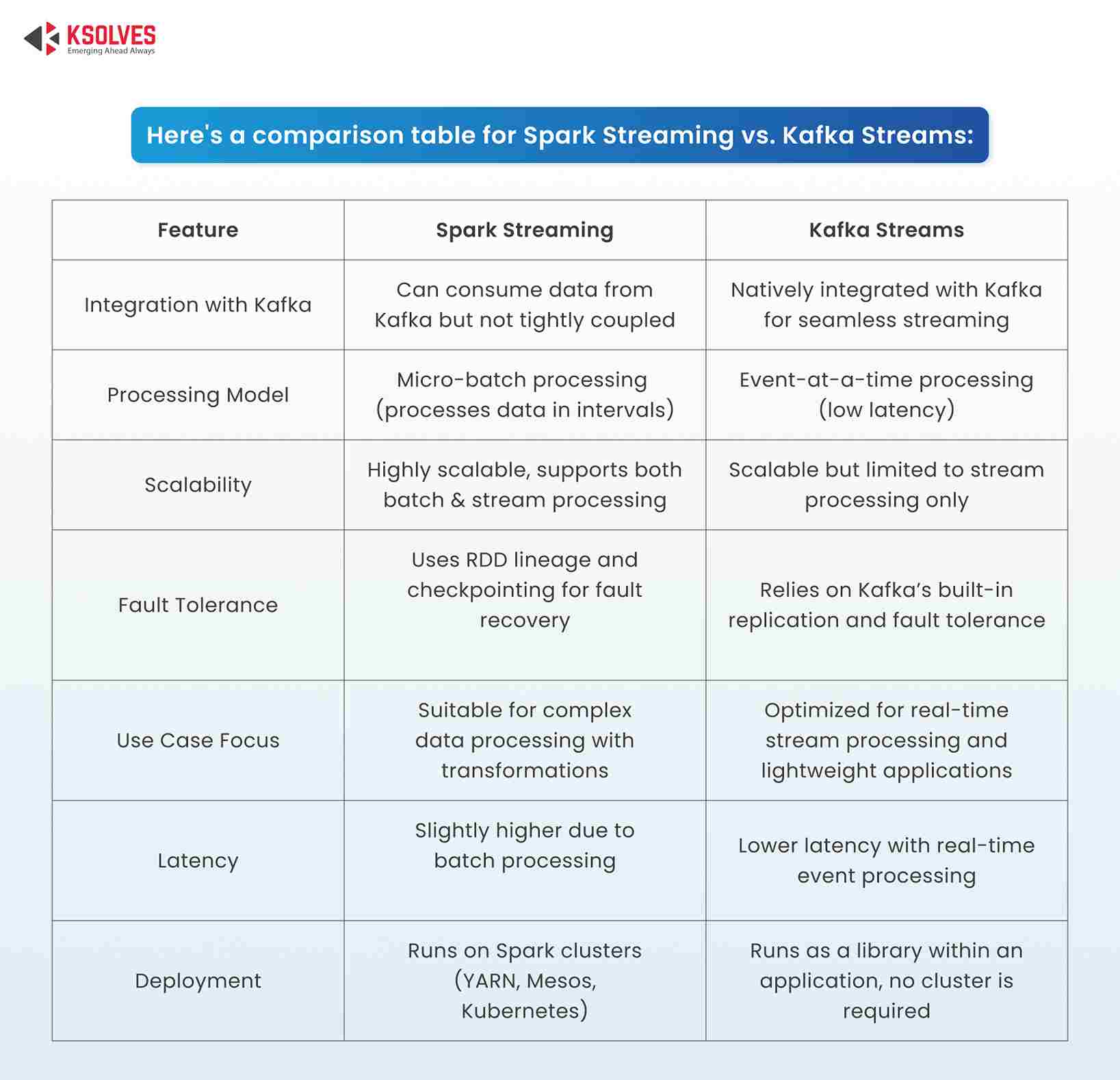
Spark Streaming vs Kafka Streaming: What’s The Difference?
While Spark Streaming is a widely used solution for real-time stream processing, it’s often compared with Kafka Streams, another popular stream processing platform built on top of Apache Kafka. Here are a few key differences:
Here’s a comparison table for Spark Streaming vs. Kafka Streams:
Hire Ksolves To Integrate Spark Streaming Into Your Data Architecture
Apache Spark Streaming provides the best solution for fast-processing data streams. If you need expert Apache Spark Support to integrate Spark Streaming into your data architecture, consider partnering with Apache Spark Development company in USA. With its expert team, the professionals will deliver custom stream processing solutions as per your specific requirements. Get a free consultation today to avail yourself of the best Apache Spark development services or reach out for expert guidance at sales@ksolves.com.
![]()











AUTHOR
Big Data
Anil Kushwaha, Technology Head at Ksolves, is an expert in Big Data and AI/ML. With over 11 years at Ksolves, he has been pivotal in driving innovative, high-volume data solutions with technologies like Nifi, Cassandra, Spark, Hadoop, etc. Passionate about advancing tech, he ensures smooth data warehousing for client success through tailored, cutting-edge strategies.
Share with