Redpanda vs Kafka: Does Redpanda Really Outperform Kafka in Terms of Performance & TCO?
Big Data
5 MIN READ
October 23, 2024
![]()

When it comes to data streaming platforms, the first name that comes to mind is Apache Kafka. In other words, we can say that Kafka has become a de-facto standard for building real-time streaming data applications and pipelines. Though other data streaming platforms, such as Apache Pulsar, RabbitMQ, Redis Streams, etc., are available, Kafka, with its widespread use, continues to be the preferred choice of many.
Recently, Redpanda has also been added to the list of Kafka alternatives. What’s more surprising is the performance claims made by Redpanda. It says that Redpanda can deliver 10x faster tail latencies with 3x fewer nodes than Apache Kafka.
On the other hand, Kafka attests that the performance entirely depends on certain factors and proves to be faster than Redpanda.
Jack Vanlightly, a principal technologist at Confluent, ran benchmarking against Redpanda and Kafka on identical hardware. He found that Kafka surpassed Redpanda in terms of performance to a large extent, offering high throughput and achieving low latencies. In contrast, he also found that Redpanda outperformed Kafka in some other tests.
So, let us decode Redpanda’s claims and understand the performance differences between Kafka and Redpanda. Also, let us have a glance at some other differences and similarities between both platforms.
An Overview of Redpanda and Kafka
Apache Kafka
Kafka, or Apache Kafka, is a distributed event-streaming platform to ingest and process high-volume, high-velocity, and fault-tolerant data streams in real-time. In addition to real-time data, it stores and processes historical data. Kafka is primarily used to develop real-time streaming data applications and pipelines, event-driven architectures, and microservices applications.
Redpanda
Redpanda, formerly known as Vectorized, is a complete Apache Kafka-compatible data streaming platform that is simpler, lighter, and faster. In other words, it is a C++ clone of Apache Kafka. Written in C++, Redpanda is developed using the Seastar framework from ScyllaDB. It is free from ZooKeeper and Java Virtual Machine (JVM), offering 10x lower latencies and reducing the cost by 6X while maintaining data safety.
The use cases of Redpanda are similar to Kafka, which include real-time analytics, stream processing, and building event-driven architectures.
Similarities Between Redpanda and Kafka
Kafka and Redpanda share many similarities in terms of features, architecture, and other factors. Let us dive into those similarities.
- Both are distributed append-only log systems with a configurable replication factor.
- Kafka and Redpanda both store messages in order, in a distributed commit log.
- Both map one partition to one active segment file rather than using a shared-log storage model like Apache Pulsar.
- They work on the concept of brokers, consumers, and producers. Producers generate data, brokers ingest that data, and consumers read it from the brokers.
- Redpanda and Kakfa both use topics, which are stored on brokers, to organize data.
- Both are resilient and fault-tolerant and let you store messages indefinitely.
- They replicate data across brokers to ensure high availability, data integrity, and continuity of the service.
Redpanda vs Kafka: Performance Comparison
There is an ongoing debate regarding the performance of Kafka and Redpanda. Redpanda, in one of the blogs, compared its performance with Apache Kafka and claimed that
A 1 GB/s workload requires only 3 i3en.6xlarge instances with Redpanda, while Kafka required 9 instances and still offers slow performance.
It seems logical to believe that this claim is true because Redpanda is built using C++ with a thread-per-core architecture.
Redpanda’s Performance Benchmark
Redpanda leveraged the Linux Foundation’s OpenMessaging Benchmark, where they conducted three tests for each workload (a 30-minute warm-up for each workload). The tests were carried out on 4 m5n.8xlarge instances, which guaranteed 25Gbps network bandwidth with 128GB of RAM and 32 vCPUs. Further, they used Kafka v3.2.0 and Redpanda v22.2.2 throughout.
The benchmark leverages three workloads: 50 MB/sec, 500 MB/sec, and 1 GB/sec.
Redpanda’s primary aim in conducting these tests was to gauge end-to-end throughput and end-to-end latency with 2 producers writing and 2 consumers reading from a single topic across multiple partitions.
They conducted all tests on AWS. They used identical instance types to run Redpanda and Kafka. Here are the details of the workloads used in testing:
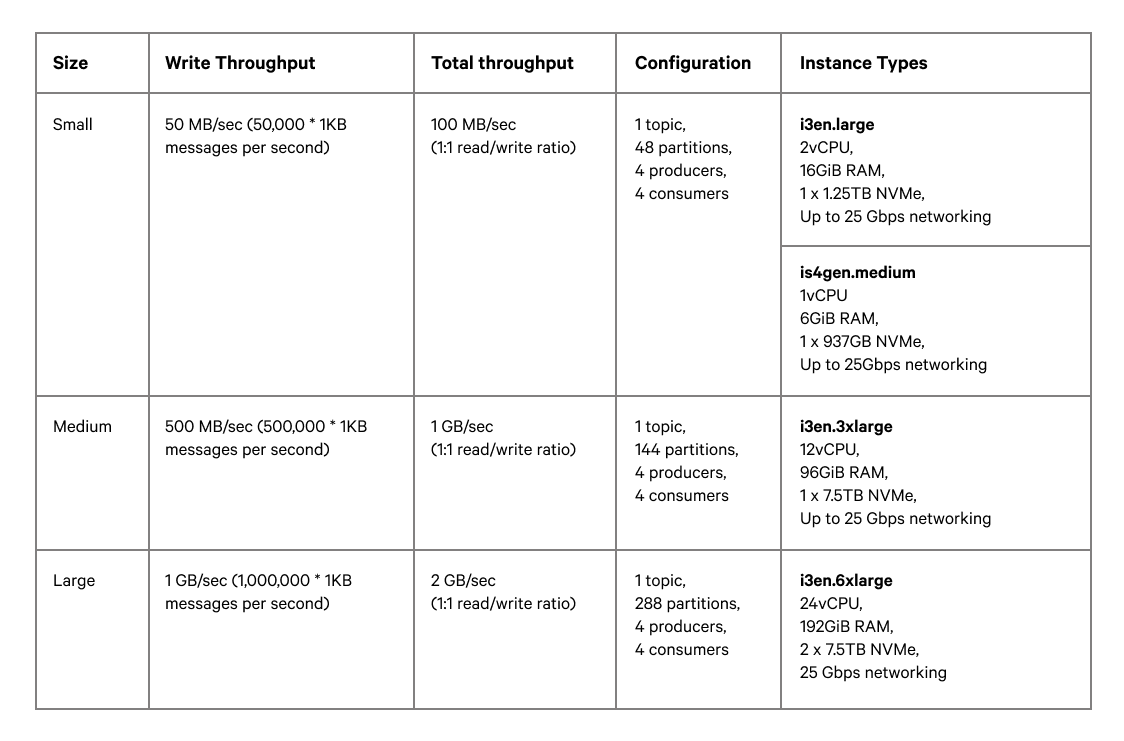 Image Source: Redpanda
Image Source: Redpanda
Here are Redpanda’s observations after rigorous 200 hours of testing with multiple combinations and permutations:
- Redpanda is 70x faster than Kafka in terms of tail latencies with medium to high workload throughput.
- Redpanda’s latencies remained stable, whereas Kafka failed to maintain its latencies even at the lowest end of the testing spectrum.
- Redpanda effortlessly exceeded the throughput capacity of 1 GB/sec. Conversely, Kafka required double the hardware and still encountered latency issues.
- Kafka’s latency was reduced by increasing the node count by 3X, whereas Redpanda performed consistently with 2-3X faster.
- Once it reached its stress limit, Kafka was not able to rectify easily even after adding more nodes.
Jack Vanlightly’s Performance Benchmark
Well, to confirm whether Redpanda’s claim is true or not, Jack Vanlightly, a principal technologist at Confluent, performed his own performance benchmark on identical hardware and observed the following:
- During the 1 GB/s benchmark, Redpanda’s performance degraded when made minor modifications to the workload, such as increasing producers from 4 to 50.
- When running for more than 12 hours, the performance of Redpanda slowed down significantly.
- The end-to-end latency of Redpanda for the 1 GB/s benchmark increased significantly when the brokers reached their data retention limit.
- When aks = 1, Redpanda failed to push NVMe drives to their throughput limit of 2 GB/s, whereas Kafka was able to do it.
- Redpanda failed to drain large backlogs, while Kafka was able to do it under constant 800 MB/s or 1 GB/s producer load.
Jack Vanlightly, in all the above circumstances, observed that Kafka’s performance surpassed Redpanda.
Here is an overview of the above observations:
| Parameters | Apache Kafka | Redpanda |
| Performance with workload modifications (e.g., increased producers from 4 to 50) | Able to handle the increased workload smoothly | Performance degraded with the increased workload |
| Long-term performance (>12 hours) | Maintained consistent performance | Performance significantly deteriorated |
| End-to-end latency at data retention limit | Latency does not increase | Latency increased considerably |
| Performance with AKS = 1 (NVMe throughput limit) | Reached throughput limit of 2 GB/s | Failed to reach the throughput of 2 GB/s |
| Drain large backlogs under constant producer load (800 MB/s or 1 GB/s) | Able to do | Not able to do |
On the contrary, he executed some other tests and noticed that Redpanda could be faster than Kafka but never in terms of throughput.
The Final Analysis?
Jack Vanlightly, after completing his performance benchmark, concluded that Redpanda can outshine only when it gets the right workload. There are many workloads where Redpanda cannot outperform Kafka. Further, he stated that Redpanda’s performance is highly unstable—batch sizes should not be too small, throughput should not be too high on high partition workloads, and many other constraints.
Regarding Kafka, Jack Vanlightly said that the page cache is both a boon and a bane. It is beneficial to attain high performance for a wide variety of workloads. On the flip side, the page cache can result in end-to-end latency spikes, affecting tail latencies.
The best decision to choose between both platforms is to carry out a performance benchmark yourself and determine the right one for your unique use case.
Redpanda vs Kafka: Other Differences
Let us now shed light on some other differences between Redpanda and Kafka.
| Parameters | Apache Kafka | Redpanda |
|---|---|---|
| License | It is open-source under the Apache License governed by the Apache Software Foundation. | It is a source available under the Business Source License (BSL). The Enterprise license provides access to proprietary paid features. |
| Contribution model | Kafka is actively managed and developed by 100+ full-time contributors, working at multiple companies. | This tool is entirely developed and maintained by Redpanda. |
| Source language | Java | C++ |
| Deployment options | Kafka can be deployed on:
|
Redpanda can be deployed on:
|
| ZooKeeper dependency | The Zookeeper dependency was removed from version 3.3+ by KRaft. | No dependency |
| Replication | Kafka uses sync replication. | Redpanda uses quorum replication (Raft). |
| Native integrations | A large ecosystem | Comparatively smaller ecosystem |
| Monitoring | Kafka requires you to set up monitoring tools, like Grafana, Prometheus, JMX, etc. | Redpanda directly integrates with monitoring tools, like Grafana and Prometheus. |
Redpanda vs Kafka: Total Cost of Ownership (TCO) Comparison
The total cost of ownership refers to an organization’s expected expense on the initial purchase or development, ongoing maintenance, upgrades, licensing fees, training, and support.
So, if you are planning to self-host Redpanda or Kafka, you must consider the following expenses:
- Infrastructure costs
- Operational costs
- Human resources
- Downtime costs
- Miscellaneous costs, such as security, compliance, auditing, integrations, etc.
Again, Redpanda claims that it requires a lower total cost of ownership (TCO) compared to Kafka, as it needs fewer nodes and has no administrative burden.
However, we believe that TCO for self-hosting Kafka or Redpanda varies depending on the cluster size, data volume, and, of course, your use case. This requires a team of skilled resources and ample time. It is better to opt for managed services for Kafka and Redpanda deployments.
At Ksolves, we help you reduce your administrative overload with our Kafka Managed Service. It helps you spin your clusters within minutes without any technical know-how. Whatever the use case may be, Kafka Managed Service lets you manage your workload without any technical complexity.
Redpanda vs. Kafka: Which One to Choose?
Rather than believing Redpanda’s claim and Jack Vanlightly’s observations, we recommend you perform your own performance benchmark and choose the right tool for your data needs.
Choose Redpanda if you:
- Are extremely end-to-end latency-sensitive.
- Want to avoid the overhead of JVM.
- Want a simple, less complex architecture.
On the flip side, choose Kafka if you:
- Prefer working with Java instead of C++.
- Have a diverse variety of workloads.
- Require an extensive set of native integrations.
Planning to adopt Kafka for your complex data needs? Don’t worry! Ksolves is a leading Apache Kafka consulting company committed to delivering excellence with 12+ years of IT expertise and a team of skilled developers. From setting up Kafka clusters to managing cluster failovers, we help you every step of the way. With our dedicated support, we ensure the uptime of your Kafka infrastructure.
![]()











AUTHOR
Big Data
Anil Kushwaha, Technology Head at Ksolves, is an expert in Big Data and AI/ML. With over 11 years at Ksolves, he has been pivotal in driving innovative, high-volume data solutions with technologies like Nifi, Cassandra, Spark, Hadoop, etc. Passionate about advancing tech, he ensures smooth data warehousing for client success through tailored, cutting-edge strategies.
Share with