Know Apache Spark Shuffle Service
Spark
5 MIN READ
January 17, 2023
![]()

One of the primary operations in memory programming in Apache Spark is shuffling. The process is responsible for managing data redistribution during Spark jobs. When a Spark job requires data to be moved between executors or between the executors and the driver, the shuffle service manages this data movement.
Although it is an expensive operation, it is still essential and is the primary operation. The apache spark shuffling serves as a separate daemon on each machine in the cluster and is responsible for the data exchange between the executors and storing the data in a local shuffle file system. It enables Spark to scale to large cluster sizes and handle data-intensive workloads.
To organize data, Spark shuffle generates sets of tasks – map tasks to organize the data and a set of reduced tasks to aggregate it (this nomenclature comes from MapReduce).
The shuffle service can be configured to use various file systems, like the local file system or HDFS, and you can also configure it to different network topologies, such as TCP, to optimize the data transfer performance.
Know Apache Spark Shuffle Service: Unveiling its Role in Big Data Processing
In the world of Big Data, the Apache Spark Shuffle Service plays a crucial role in enabling efficient data processing. Whether you’re running complex machine learning models or large-scale data analytics, understanding the shuffle service is essential for optimizing performance.
The shuffle service is responsible for redistributing data across Spark executors during shuffle operations—where data is transferred between stages of a distributed job. This process is key for executing tasks like sorting, joining, or aggregating large datasets. By managing the intermediate data exchange, the shuffle service helps ensure that jobs run faster and more efficiently.
In our video, “Empower Your Data with Ksolves’ Big Data Solutions,” our expert dives deep into how Apache Spark and its shuffle service contribute to building data-driven solutions. Discover how you can leverage this vital component to improve the speed and accuracy of your data analytics processes, enabling your business to gain real-time insights and make strategic decisions with confidence.
Feel free to watch the full video below to explore the technical breakdown of Apache Spark’s Shuffle Service and other Big Data technologies:
Continue reading to learn more about Apache Spark Shuffle Service!
What Is A Shuffle?
To know when a shuffle occurs, it is essential to understand how scheduling works on Spark for the workloads on the cluster. Generally, the shuffle happens between the two stages. When the DAGScheduler produces the physical execution of the plan for the logical plans, it will connect all the RDDs into a single stage connected through narrow dependency.
Consequently, it will cut the logical plan between the RDDs with broad dependencies. The last stage that it generates is known as the ResultStage. All types of stages are needed for computing the ResultStage, known as the ShuffleMapStages.
By the ShuffleMapStage definition, the occurrence of the data redistribution before running the subsequent stage. Therefore, each stage has to end with a shuffle. We can consider it the physical execution plan with a map steps series to exchange the data according to the dividing function.
Put in simple words, shuffling the data exchange process between the partitions. It results in data rows moving between the worker nodes when their source divides and targets the partition residing on a different machine. Spark does not shift the data randomly between the nodes. Shuffling consumes a lot of time, which is why most companies do it when there is no other option.
Working of Spark Shuffle
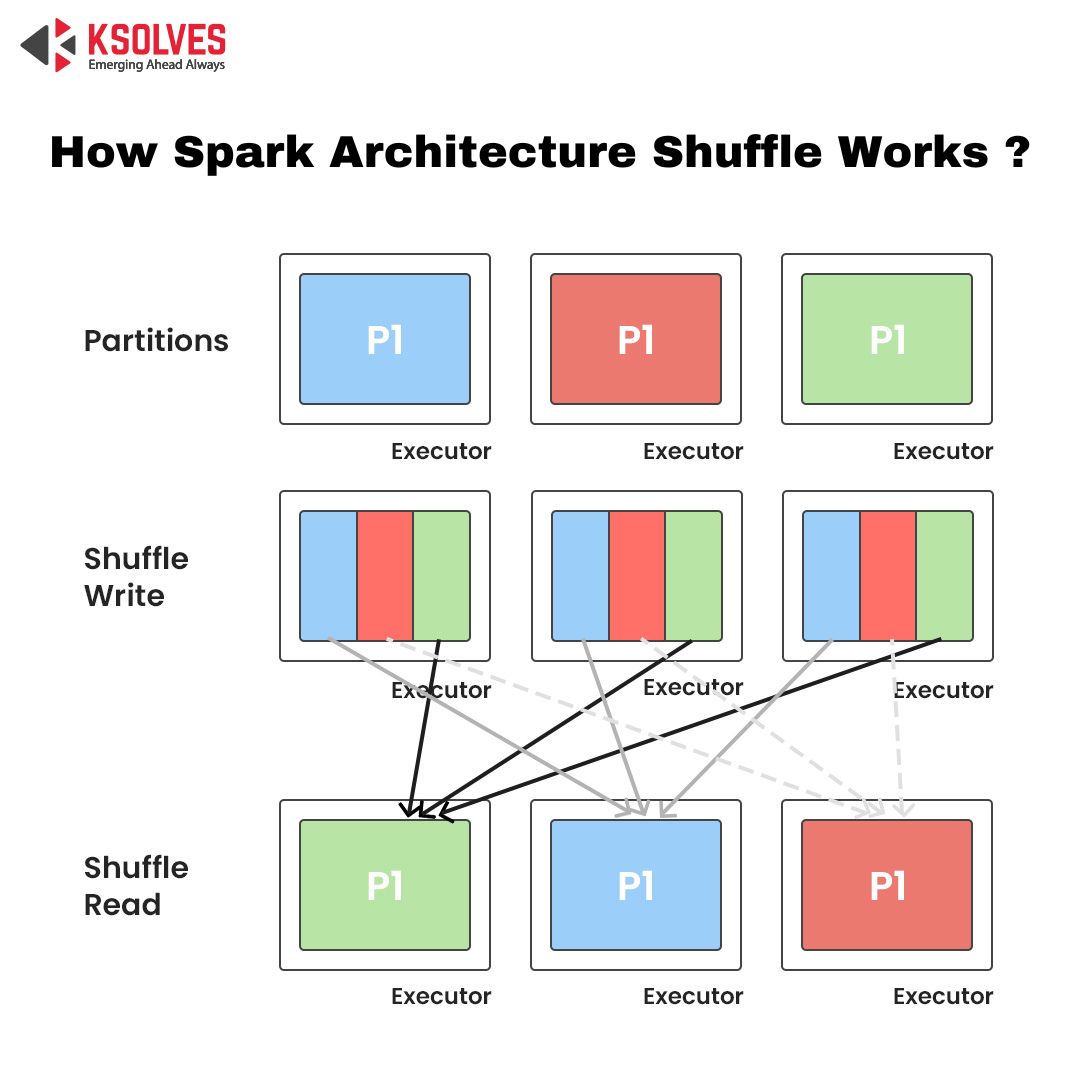
The data is returned to the disk during the shuffle and transferred to the network. The role of the shuffle is to reduce the number of reductions which happens to reduce the shuffled data amount. Generally, spark shuffle services consist of the hash, which helps to determine the primary value pair which will go to the machine.
The spark shuffle will use the pull model. Each map task writes the data to the disk. As shuffle occurs to all-to-all operations, it will reduce some of the unnecessary records to make the task more efficient. The role of the shuffle’s map side is to write the records to ensure that these records are in the sequence for the same reduced task, which is grouped next to one another to make fetching more accessible.
Many top companies, such as Uber, run Spark on the Apache Yarn and use Spark’s External Shuffle to perform shuffle.
Different Implementations Of Shuffle Services
-
In Built Shuffle Service
It is also known as the NO External Shuffle service. In this, the Spark Executor will do its task on its own. Although with these options, Spark will work fine, you will begin to see its effects once the executor stops. It will remove the generated files. But when you enable the service, the files will not be cleaned after shutting down the executor. So, in this case, you will have to use the Spark Shuffle service since or else there will be chances of data loss when the executor is eliminated, which can significantly and negatively affect the application’s performance.
Another side effect can occur with this approach when the executors are running the tasks, but other executors request the data shuffling. If the executor fails to respond to the block request in the time application, there will be fetched failure errors, which will ultimately reduce the application’s performance. This issue can be resolved by changing the spark configurations to:
- spark.shuffle.io.maxRetries
- spark.shuffle.io.threads
- spark.rpc.io.threads
- spark.shuffle.io.clientThreads
-
YARN Shuffle Services
It is the shuffle service on the YARN. To use this implementation of the Shuffle service on the YARN, the user must start the Spark Shuffle service on every NodeManager in the YARN cluster. There is an extra YARN implementation as the Cluster Manager, but the goal and process are the same as the Shuffle Service used on the standalone cluster manager.
-
Standalone Shuffle Services
Executors work and communicate with the external shuffle service, which uses the RPC protocol. They generally send messages to OpenBlocks and RegisterExecutor. The RegisterExecutor is utilized when the executor registers inside the local shuffle server. OpenBlock is used in the block fetching process. The BlockManager conducts both actions through their shuffleClient.
The external shuffle services enabled in the configuration are used in either NettyBlockTransferService or the org.apache.spark.network.shuffle.ExternalShuffleClient.
-
Mesos Shuffle Service
It is the shuffle service for Mesos. The process is simple and similar to the YARN and is Standalone.
-
Cosco
The Facebook warehouse uses this for powering the spark and hive jobs. It is used and integrated as a reliable, maintainable, scalable distributed system. The primary differentiator is the partial in-memory aggregation across the distributed memory pool. Cosco offers enhanced efficiency in disk usage than the built-in Shuffle of the Spark.
-
Kubernetes Shuffle Services
Although when you use Kubernetes, it will not support the external shuffle service. However, some implementations are available that use the DaemonSet, which runs the shuffle-service pod on every node. The shuffle-service pods and executors pods will land on the same node share disk using the host path volumes. Spark needs each executor to know the IP address of the shuffle-service pod sharing the disk.
-
Riffle
This service of the Shuffle enhances the I/O efficiency and scales to process the data petabytes. Riffle will merge the fragmented intermediate shuffle files into one large block file. It will convert the random disk I/O request to a sequential one. Riffle will enhance the fault and performance by mixing the unmerged and merged block files to reduce the merge operation overhead. With Riffle, Facebook produces jobs on the spark clusters with more than 1,000 executors, up to a 10x reduction of the shuffle I/O request. It will also enhance end-to-end job completion by 40%.
-
Alibaba’s EMR Remote Shuffle Service
This service of the Shuffle is developed at the Alibaba cloud for the serverless Spark use case. It consists of three primary roles, worker, client, and master. The worker and master constitute the server. The client integrates the Spark in a non-intrusive manner. The master role is to work for state management and resource allocation.
The worker processes and keeps the shuffled data. The client caches and pushes the shuffled data. It adopts the shuffling mode in the push style. Each mapper consists of the cache, which is delimited by the partition. The data of the shuffle is written in the cache. A push data request is used when the partition cache is full.
-
Zeus
It is a distributed shuffle service that Uber implements. Uber runs the biggest Hive and Spark clusters on top of the YARN in the industry, which leads to several issues, such as scalability and reliability challenges, as well as hardware failures. Zeus is known for supporting countless jobs and several containers which shuffle the shuffle data petabytes.
What Is Apache Spark External Shuffle Service?
Initially, many people think that the external shuffle service is the distributed component of the Apache Spark cluster which is responsible for storing shuffle blocks. However, it is much simpler. The external shuffle service is the proxy through which the spark executor fetches the block. Hence, the lifecycle is not dependent on the executor lifecycle.
When enabled, services will be working on the worker node and creating the new executor that registers to it. In the registration, the executor will inform the service about storing the disks where files are created. With this information, the external shuffling service daemon can return the files to other executors in the retrieval process.
External shuffling services also affect file removal. Normally, when the executor is eliminated, it will remove the generated files. However, the files will not be cleaned in the enabled services even after shutting down the executor.
Why Choose Ksolves?
The Apache Spark solutions will enable the process in vast data streams at a quick speed. Identify better patterns and insights, complement the real-time data analysis, and the simultaneous data operations with Ksolves. Ksolves can help you to adapt to Apache Spark from the current data systems and get a single access point with integrated data benefits.
You need our consulting services to acquire guidance and clarity on how well this data management system will transform the enterprise approach for the data. We are efficient in different data libraries such as data streaming, graph algorithms, machine learning, and SQL queries other than the tools for the reduction and MAP. Connect with us, and we can help you with the Apache Spark Shuffling services.
Connect us at sales@ksolves.com for a free consultation.
Apache Spark and Cassandra: A Powerful Combination for Big Data
The Spark Shuffle Service is essential for managing data movement between different stages of a Spark application. However, when dealing with vast amounts of data, you need a reliable database to store and retrieve information efficiently—this is where Apache Cassandra comes in. Cassandra’s distributed architecture makes it an ideal companion for Apache Spark, allowing for real-time data storage and processing at scale.
At Ksolves, we offer expert Apache Cassandra development services with a team of Datastax-certified professionals and 50+ skilled developers. Our 12+ years of experience and 30+ successful projects ensure that we can seamlessly integrate Cassandra with your Spark workloads for optimized performance.
Watch this video to learn more about how we can help you harness the power of Apache Cassandra for your big data projects:
By combining Apache Spark for fast processing and Cassandra for scalable storage, you can build a powerful, high-performing big data infrastructure. Let us help you achieve real-time analytics and data flow management with this winning combination.
Conclusion
These are the top uses and implementations of successful Apache Spark Shuffling services. Apache Spark is one of the best tools that will help enterprises manage vast data; the seamless integration and specifications of the tool make it the best for data management.
![]()
Frequently Asked Questions
Why do we need Spark Shuffle Services?
If the Spark external services are on, it will manage the shuffle data rather than the executors. It assists with the downscaling of the executors since the data will be saved after removing them.
What is Apache Spark Shuffle?
The shuffle is the process between the map task and the reduce task. The term shuffling refers to the given data shuffles.
What is the YARN shuffle service?
It is an external shuffle service on YARN by Spark. The node manager auxiliary of the YARN services implements the org. Apache. Hadoop.
What is the role of Shuffle in Hadoop?
The Hadoop Shuffle phase transfers the map output from the mapper to the reducer in MapReduce.





AUTHOR
Spark
Atul Khanduri, a seasoned Associate Technical Head at Ksolves India Ltd., has 12+ years of expertise in Big Data, Data Engineering, and DevOps. Skilled in Java, Python, Kubernetes, and cloud platforms (AWS, Azure, GCP), he specializes in scalable data solutions and enterprise architectures.
Share with