The Role of Apache Spark in the Big Data Industry
Spark
5 MIN READ
May 16, 2022
![]()

Hadoop has already shown its potential benefits in the big data industry by giving better data insight for business growth. It has redefined the Big data domain with its outstanding capability of big data processing by using batch processing. But, after introducing Apache Spark into the Big Data industry, enterprises have exceeded their expectations to get quick generation of analytics reports, data processing, and querying. As enterprises are trying to collect large volumes of data, it has become a major challenge for them to process, analyze, and explore the unstructured data. It is here that Apache Spark comes into the picture with its unbeatable big data processing capability using batch processing.
What is Apache Spark?
Apache Spark is a powerful and fast open-source cluster computing framework with an increasing number of use cases in the industry. The key features such as speed and scalability makes it a great alternative to Hadoop. It is much faster than Hadoop, especially with batch processing, which allows it to deal with huge datasets in just a matter of a few minutes.
Apache Spark is the future of big data platforms. In this blog, we are discussing different aspects that increase the importance of Apache Spark in the Big Data industry.
How does Apache Spark improve businesses in the Big Data industry?
The foremost reason why Apache Spark is ruling in the big data industry is its outstanding in-memory data processing. Most tasks of Apache Spark take place in in-memory. This makes it faster and more optimized as compared to other approaches like Hadoop’s MapReduce. Apache Spark has outstanding potentials that can boost the big data-related businesses in the industry. . Let’s read about its key advantages for businesses:
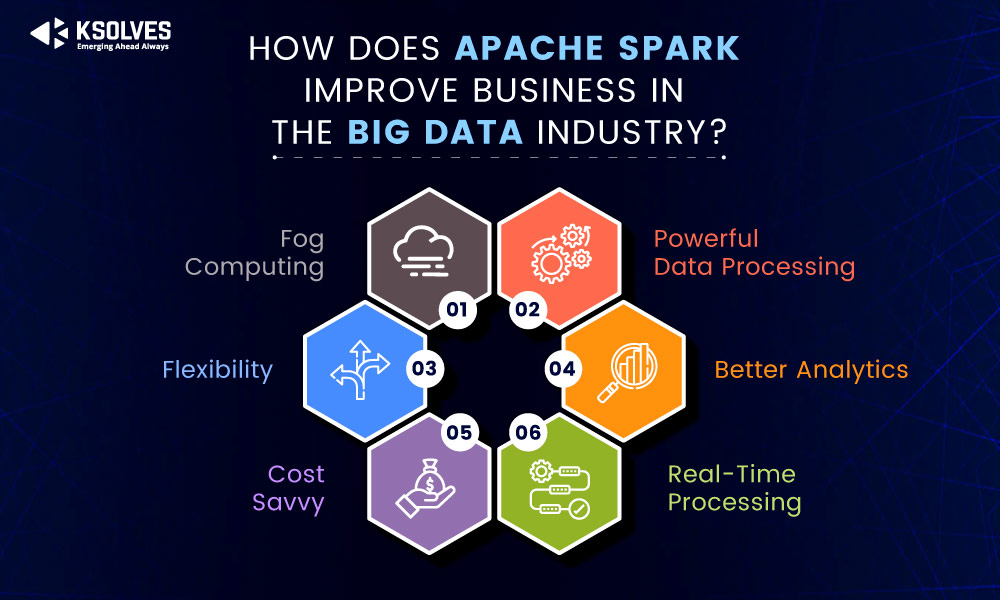
- Powerful Data Processing– Apache Spark is an ideal tool for companies that work on the Internet of Things. As it has low-latency in-memory data processing capability, it can efficiently handle a wide range of analytics problems. It contains well-designed libraries used for graph analytics algorithms and machine learning.
- Better Analytics: Apache Spark libraries are used by big data scientists to improve their analyses, querying, and data transformation. It helps them to create complex workflows in a smooth and seamless way. Apache Spark is used for completing various tasks such as analysis, interactive queries across large data sets, and more.
- Real-time processing. Apache Spark enables the organization to analyze the data coming from IoT sensors. It enables easy processing of continuous streaming of low-latency data. In this way, organizations can utilize real-time dashboards and data exploration to monitor and optimize their business.
- Fog computing– After IoT, Fog computing is coming to be the next biggest thing in the realm of decentralized data processing. Apache Spark has great potential to analyze the huge amount of distributed data, which proves beneficial for organizations to create IoT-based applications for new businesses.
- Cost-Savvy: There is no need to create a new setup for Apache Spark because it can work on top of the existing Hadoop Distributed File System (HDFS). Organizations can put Spark on the same Hadoop cluster with the same data and cluster. It proves a highly cost-savvy enhancement for businesses.
- Flexibility– Apache Spark is highly compatible with a variety of programming languages and allows you to write applications in Python, Scala, Java, and more.
Common User Cases for Apache Spark
One of the primary reasons for using Apache Spark in Big data is its speed. Because of its high processing speed, it ensures faster data processing of multiple big data tasks, which is important in machine learning. Apart from this, there are many properties that make Apache Spark a perfect choice from a practical point of view.
1. Streaming and Processing
One of the effective abilities of Apache Spark is to process streaming data. Every second, huge amounts of data is created around the world. Companies are required to process such large data in real-time. It becomes difficult for professionals to manage the “streams” of data. In this scenario, Spark Streaming features prove highly beneficial for the company. These are used for batch processing and real-time processing. Many companies are using Spark because of this amazing streaming feature.
- Streaming ETL: Unlike traditional ETL tools used in data warehouse environments for batch processing, Spark Streaming ETL first reads the data to convert it to a database compatible format and then writes it to the targeted database. It efficiently cleans and aggregates the data before putting it into the data repositories.
- Data Enrichment: This feature is beneficial for boosting data quality by mixing it with static data that enables real-time data analysis. Data enrichment capabilities are used by online markets to combine previous customer data history with actual customer behavior data.
- Trigger event detection:With this capability you can quickly detect and respond to unexpected trigger events or behaviors that can harm the system or lead to severe problems. Financial firms are using this feature to detect fraudulent transactions, whereas healthcare professionals use it to detect dangerous health changes in patients’ health and alert caregivers to take immediate action.
2. Advanced Analytics
Spark provides various outstanding benefits that play well in attracting users. As compared to Hadoop, it has outstanding speed and suitability for handling iterative computations. Advanced analytics makes extensive use of iterative computations. For many companies it is easy to work with Apache Spark. There are many companies who have started creating their own Spark libraries for clustering, regression and classifications. The Spark tools and libraries help in solving various glitches of modern world issues such as online advertising and marketing, scientific research, and fraud detection. With this, it becomes easy to develop such libraries for graph and machine learning analytics.
3. Machine Learning
Apache Spark comes with outstanding machine learning skills. It has a built-in framework which allows you to perform advanced analytics and run several queries on the datasets. Machine Learning Library (MLlib) is an outstanding component provided by Spark . With this library package, you can perform clustering, dimensionality reduction, and many more. Another worth mentioning application of Spark is network security.
Security providers/companies can easily scan data packets in real-time to trace malicious activity by using the various available components of the Spark stack. They can use Spark Streaming to check unknown dangers before sending the packets to the repository.
Conclusion
In the Big Data business, Apache Spark is generally used for interactive scaling of batch data processing requirements. Furthermore, it is likely to play a crucial part in the future generation of business intelligence applications.
At Ksolves, we are reckoned as one of the most trusted Apache Spark development companies in the USA and India. We have a proven track of successfully delivering projects with happy and satisfied clients’ feedback. We are backed by a highly skilled and experienced team of Apache Spark developers who directly work with the clients to provide customized solutions for better growth.
Frequently asked question (FAQ)
What is the purpose of using Apache Spark?
Apache Spark is an open- source distributed processing solution which is used for managing huge amounts of big data workloads. When it comes to fast analytic queries against any size of data, it utilizes in-memory caching and efficient query execution.
What are the Apache Spark components?
Spark Core, Spark SQL, Spark Streaming MLlib, Spark R, and GraphX are all key parts of the Apache Spark Ecosystem. All these components enable Apache Spark.
What is the Apache Spark tool?
Apache Spark tools are the key software features of the Spark framework. These tools are used for efficient and scalable data processing in big data analytics. It contains five important tools for data processing, such as MLlib, GraphX, Spark Core, Spark SQL, and Spark Streaming.
What types of problems does Apache Spark solve?
As compared to MapReduce, Apache Spark offers a highly functional programming model. Spark Core is the foundation for parallel and distributed data processing on a large scale. It is responsible for:
Distributing, scheduling, and job monitoring in a cluster
Interaction with storage systems
Fault recovery and memory management
What advantages does Spark have over MapReduce?
As compared to Hadoop MapReduce, Apache Spark is potentially 100 times faster. Apache Spark runs in RAM and isn’t bound by Hadoop’s two-stage architecture. Apache Spark can work well with smaller data sets which can fit into a server’s RAM.
![]()











AUTHOR
Spark
Atul Khanduri, a seasoned Associate Technical Head at Ksolves India Ltd., has 12+ years of expertise in Big Data, Data Engineering, and DevOps. Skilled in Java, Python, Kubernetes, and cloud platforms (AWS, Azure, GCP), he specializes in scalable data solutions and enterprise architectures.
Share with