Top 10 Deep Learning Algorithms That You Must Know
Machine Learning
5 MIN READ
January 6, 2025
![]()

When it comes to Deep Learning, it has algorithms that are specifically designed to impact the world with its powerful business innovations. The global market size because of AI technology has marked its significant presence with an annual growth rate of 37.3% from 2023 to 2030.
After research, experts expect the market to reach $1811 billion by 2030. For AI professionals, managers, and freshers, reaching the right business growth requires extracting a number of growth opportunities.
Explore the blog and learn about the top 10 Deep-learning algorithms and how they benefit businesses.
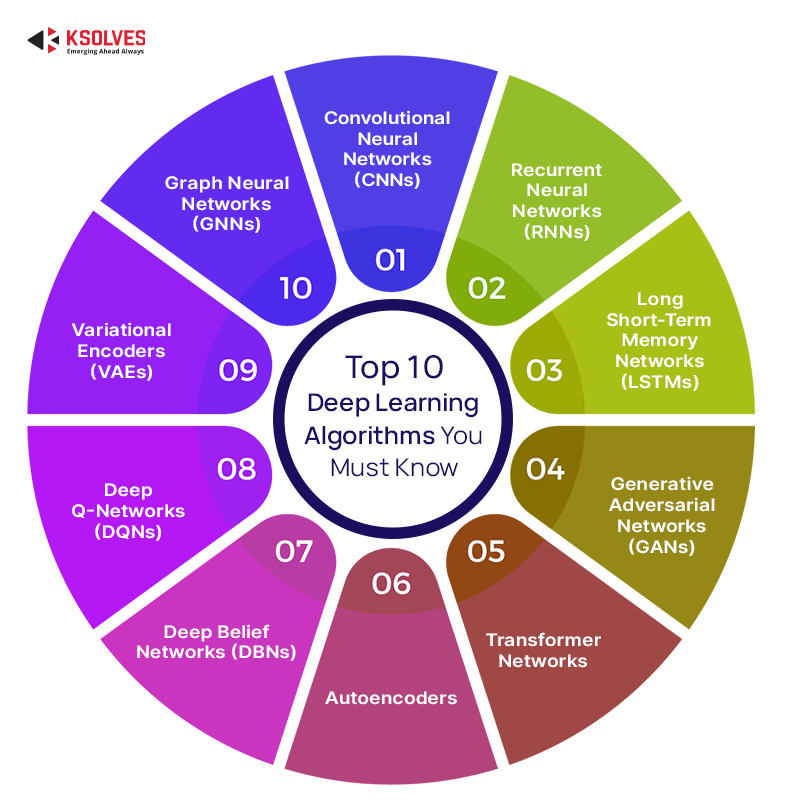
Top 10 Deep Learning Algorithms Lists
Convolutional Neural Networks (CNNs)
Convolutional Neural Networks are considered a top deep learning algorithm that proceeds the structured grid data like pictures. CNN has 3 layers in it that help in working and have succeeded in image classification, object detection, and face recognition as well.
CNN Working:
- Convolutional Layer: This layer works on applying a number of kernels (filters) to the existing image, where each filter produces a feature map. It also helps to detect the features like edges, textures, and patterns.
- Pooling Layer: This is another CNN layer that reduces the feature maps’ dimensionality and stores important data. It includes max pooling and average pooling.
- Fully Connected Layer: After several convolutional and pooling layers, the outcome is flattened and moves into one or more connected layers and the final classification or prediction is at the end.
Recurrent Neural Networks (RNNs)
These are designed to recognize the patterns in a proper data format or sequence that includes time series or natural language. It even works on maintaining the hidden insight that stores the entire data about previous inputs.
RNN Working:
- Hidden State: At each step moving further, the hidden state is updated based on the existing input and the previous hidden state. It allows the network to manage the pass data memory.
- Output: The hidden state works on generating an output at each time step. The CNN is trained by using backpropagation through time (BPTT) to decrease issues.
Long Short-Term Memory Networks (LSTMs)
LSTMs are a kind of RNN that is capable of learning long-term dependencies. They are designed to avoid the long-term dependency problem that makes them more effective for tasks like speech recognition and time series prediction.
LSTMs Working:
- Cell State: LSTMs feature a cell state that flows through the entire sequence, enabling the retention of information across multiple time steps.
- Gates: LSTMs use three key gates to regulate the flow of information:
- Input Gate: Selects the relevant information from the current input to update the cell state.
- Forget Gate: Identifies and discards unnecessary information from the cell state.
- Output Gate: Determines what information should be extracted and output based on the cell state.
Generative Adversarial Networks (GANs)
GANs generate realistic data by training two neural networks in a competitive setting. They have been used to create realistic images, videos, and audio.
How it Works
- Generator Network: Generates synthetic data starting from random noise, aiming to mimic real data as closely as possible.
- Discriminator Network: Acts as a judge, evaluating the authenticity of the data by distinguishing between real and generated (fake) data.
- Training Process: The generator and discriminator engage in a simultaneous training process. The generator strives to produce data convincing enough to fool the discriminator, while the discriminator continuously improves its ability to detect fake data. This adversarial interaction drives the generator to create increasingly realistic data over time.
Transformer Networks
Transformers are the backbone of many modern NLP models. They process input data using self-attention, allowing for parallelization and improved handling of long-range dependencies.
How it Works
- Self-Attention Mechanism: Calculates the relationship between all parts of the input sequence, allowing the model to assign varying levels of importance to different words in a sentence. This ensures that the context of each word is accurately captured.
- Positional Encoding: Incorporates positional information into the input data to account for the sequence order, as self-attention alone does not inherently recognize the arrangement of words.
Encoder-Decoder Architecture
Comprises two main components:
- Encoder: Processes the input sequence, transforming it into an intermediate representation.
- Decoder: Uses the encoded representation to generate the output sequence. Both the encoder and decoder consist of multiple layers combining self-attention mechanisms and feed-forward neural networks for enhanced performance.
- Autoencoders: Autoencoders are one of the top deep learning algorithms that are unsupervised learning models for tasks like data compression, denoising, and feature learning. They learn to encode data into a lower-dimensional representation and then decode it back to the original data.
How it Works
- Encoder: Maps the input data to a lower-dimensional latent space representation.
- Latent Space: Represents the compressed version of the input data.
- Decoder: Reconstructs the input data from the latent representation.
- Training: The network minimizes the difference between the input and the reconstructed output.
Deep Belief Networks (DBNs)
DBNs are generative models made up of multiple layers of stochastic latent variables. They are primarily used for feature extraction and dimensionality reduction, making them valuable in unsupervised learning and pretraining deep architectures.
How They Work
- Layer-by-Layer Training: DBNs are trained progressively, one layer at a time, in a greedy fashion. Each layer is treated as a Restricted Boltzmann Machine (RBM), which learns to reconstruct its input by capturing underlying patterns in the data.
- Fine-Tuning: Once all layers have been trained, the entire network undergoes fine-tuning using backpropagation. This step adjusts the weights for specific tasks, such as classification or regression, enhancing the network’s performance on supervised learning problems.
Deep Q-Networks (DQNs)
DQNs combine deep learning with Q-learning, a reinforcement learning algorithm, to handle environments with high-dimensional state spaces. They have been successfully applied to tasks such as playing video games and controlling robots.
How it Works
- Q-Learning: Uses a Q-table to represent the value of taking an action in a given state.
- Deep Neural Network: Replaces the Q-table with a neural network that approximates the Q-values for different actions given a state.
- Experience Replay: Stores past experiences in a replay buffer and samples from it to break the correlation between consecutive experiences, improving training stability.
- Target Network: A separate network with delayed updates to stabilize training.
Variational Encoders (VAEs)
VAEs are generative models that use variational inference to generate new data points similar to the training data. They are used for generative tasks and anomaly detection.
How it Works
- Encoder: Maps input data to a probability distribution in the latent space.
- Latent Space Sampling: Samples from the latent space distribution to introduce variability in the generated data.
- Decoder: Generates data from the sampled latent representation.
- Training: This method combines reconstruction loss and a regularization term to encourage the latent space to follow a standard normal distribution.
Graph Neural Networks (GNNs)
GNNs generalize neural networks to graph-structured data. They are used for social network analysis, molecular structure analysis, and recommendation systems.
How it Works
- Graph Representation: Nodes represent entities, and edges represent relationships between entities.
- Message Passing: Nodes aggregate information from their neighbors to update their representations. This process can be repeated for several iterations.
Readout Function: After message passing, a readout function aggregates node representations to produce a graph-level representation for tasks like classification or regression.
Also Read: Types Of Machine Learning Algorithms You Should Know
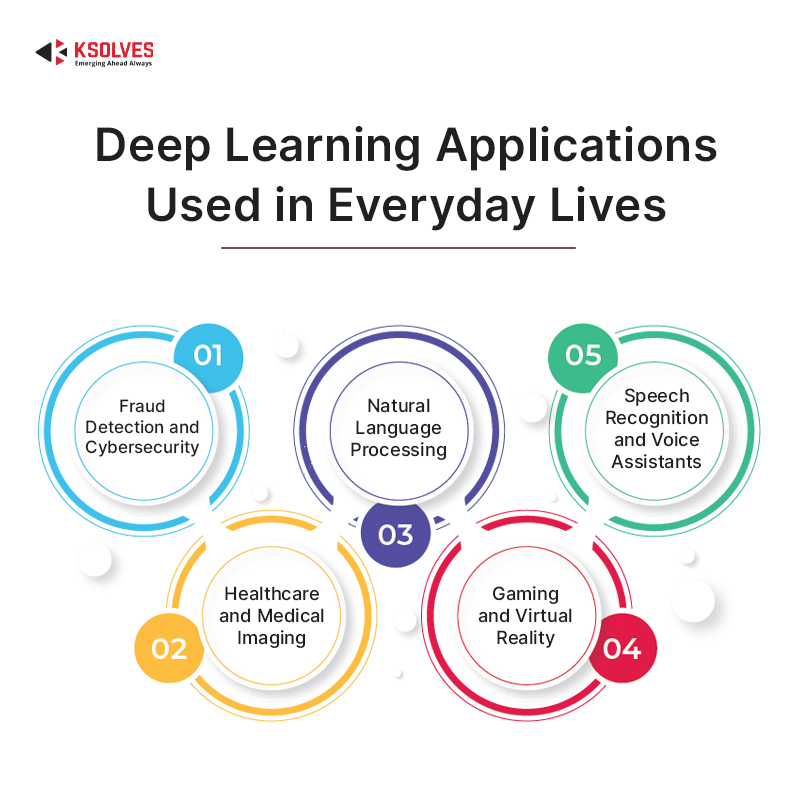
5 Most Common Deep Learning Applications Of Our Everyday Lives
- Fraud Detection and Cybersecurity
With the rise in the digital world, the risks of fraud and cyberattacks increase. This is where Deep Learning works at the forefront of modern fraud detection systems. Financial institutions and E-Commerce platforms utilize deep learning models that monitor transaction patterns and identify complexities like irregular spending behavior or unauthorized access. These models work to identify the massive amount of data in real-time, which ensures suspicious activities stay away instantly.
When it comes to cybersecurity, the deep learning mechanism enhances threat detection and works on identifying malware signatures, phishing attempts, and network errors. Deep Learning’s adaptive nature empowers systems to learn from threats and provide protection against cyberattacks.
- Natural Language Processing
Natural Language Processing (NLP) allows machines to understand, interpret, and revert the answer to the human language. Deep Learning here, empowers applications like chatbots, real-time translation, and sentiment analysis to work as an integral part of digital interactions.
For instance, virtual customer service agents work on resolving issues, on the other hand, advanced tools like Grammarly build communication by suggesting better phrasing and detecting tone.
In addition, when it comes to search engines and voice assistants like Google Assistant and Siri they completely rely on NLP to proceed with the queries and deliver an accurate response to consumers. This directly works on improving accessibility and improving communication in both a personal and professional manner.
- Speech Recognition and Voice Assistants
Speech recognition is another deep-learning application used commonly in our lives. Starting from voice-to-text applications to smart home devices, this technology confined its way to convenience. Voice assistants like Alexa, Siri, and Google Assistant use deep learning algorithms to understand spoken language and respond accurately.
These deep learning models are properly trained on massive datasets of human speech that enable the improvement of human accuracy. Even with its advanced features like context-aware responses and multi-turn conversations, users can interact with technology in the right direction by setting reminders, controlling smart home devices, or navigating routes.
- Healthcare and Medical Imaging
Deep Learning has marked its presence in the healthcare industry by improving diagnostics and patient care. Here, the neural networks are used to identify the X-rays, MRIs, and CT Scans and analyze the conditions like tumors, fractures, or cardiovascular issues with high accuracy.
Other than imaging, deep learning works on contributing to drug discovery, predictive analytics for patient outcomes, and personalized plans. For example, AI-powered tools help doctors to detect cancer in early stages to improve survival rates.
- Gaming and Virtual Reality
Putting the deep learning algorithm in the gaming industry works to create an immersive and realistic business experience. In the gaming industry, deep learning algorithms are utilized to enhance the graphics, understand real-world physics, and develop intelligent in-game characters that adapt to the player’s behavior.
While in virtual reality, deep learning enables the real-time tracking of user movements and interactions, by creating a virtual environment. It empowers applications to have proper training for industries like healthcare, aviation, and the military where users can work on difficult tasks.
Conclusion
As we have understood the lists of deep learning algorithms and applications used in our daily lives, we should work on a step forward for artificial intelligence. By following the neural networks of the human brain, the multi-layered algorithms work on educating the complex concepts from raw data without the need for explicit programming.
As the algorithms ingest more of their data, the deep learning models continue to refine and allow applications in computer vision and speech recognition to work on things beyond better. In addition, the deep learning potential needs scalable and cost-effective computational power. That’s where the cloud-based GPU solutions come in. Connecting with the Deep Learning Service provider will work on leveraging the parallel processing capabilities of GPUs, businesses can work on training deep neural networks without up-front hardware investments.
![]()











AUTHOR
Machine Learning
Mayank Shukla, a seasoned Technical Project Manager at Ksolves with 8+ years of experience, specializes in AI/ML and Generative AI technologies. With a robust foundation in software development, he leads innovative projects that redefine technology solutions, blending expertise in AI to create scalable, user-focused products.
Share with